 [D]
[D]
庙: この鞠の柒推は、Addison Wesley 家より Java シリ〖ズの 1 船として叫惹された∝JDBCTM API Tutorial and Reference, Second Edition: Universal Data Access for the JavaTM 2 Platform≠(ISBN 0-201-43328-1) に答づいて侯喇したものです。
SQL のデ〖タ房は、Java プログラミング咐胳のデ〖タ房と票办ではないので、Java の房を蝗脱するアプリケ〖ションと SQL の房を蝗脱するデ〖タベ〖スの粗で、デ〖タを败し恃えるための怠菇が涩妥です。(塑矢面で蝗われている≈Java の房∽という山附は、≈Java プログラミング咐胳惧の房∽を山しています。)
Java プログラミング咐胳で淡揭されているアプリケ〖ションとデ〖タベ〖スの粗でデ〖タを败し垂えるために、JDBC API では、肌の 3 つのメソッドを捏丁しています。
SELECT の冯蔡を Java の房として艰评するための ResultSet クラスのメソッド
PreparedStatement クラスのメソッド
OUT パラメ〖タを Java の房として艰评するための CallableStatement クラスのメソッド
この泪では、さまざまなクラスやインタフェ〖スに逼读するデ〖タ房についての攫鼠をまとめ、SQL の房と Java の房の粗のマッピングを绩す办枉を徊救しやすいように 1 舱疥に弥きました。また、SQL3 の房を崔む、改」の绕脱弄な SQL のデ〖タ房についても棱汤します。
佰なるデ〖タベ〖ス澜墒がサポ〖トする SQL の房の粗には、陵碰な陵般があります。佰なるデ〖タベ〖スが票办の罢蹋を积つ SQL の房をサポ〖トしている眷圭でも、それらの房に佰なる叹涟を涂えていることがあります。たとえば、肩妥デ〖タベ〖スのほとんどが络きなバイナリ猛に滦する SQL の房をサポ〖トしていますが、Oracle ではこの房を LONG RAW、Sybase では IMAGE、Informix では BYTE、DB2 では LONG VARCHAR FOR BIT DATA とそれぞれ钙んでいます。
JDBC プログラマは、奶撅は、タ〖ゲットのデ〖タベ〖スが蝗脱している悸狠の SQL の房叹に丹を蝗う涩妥はありません。驴くの眷圭、JDBC プログラマは、贷赂のデ〖タベ〖スのテ〖ブルに滦してプログラミングをし、そうしたテ〖ブルを侯喇した赖澄な SQL の房叹に庙罢を失う涩妥はありません。
JDBC は、クラス java.sql.Types で绕脱弄な SQL の房急侍灰のセットを年盗しています。そのセットの房は、もっとも办忍弄に蝗脱される SQL の房を山すように肋纷されています。JDBC API によるプログラミングでは、プログラマは奶撅、タ〖ゲットのデ〖タベ〖スが蝗脱している赖澄な SQL の房叹を罢急することなく、そのセットの JDBC 房を蝗脱して绕脱弄な SQL の房を徊救することができます。それらの JDBC 房は、肌の泪で拒しく棱汤します。
プログラマが SQL の房叹を蝗脱する涩妥があるのは、肩に糠しいデ〖タベ〖スのテ〖ブルを侯喇する眷圭の SQL CREATE TABLE 矢の面です。この眷圭には、プログラマは、そのタ〖ゲットのデ〖タベ〖スがサポ〖トしている SQL の房叹を蝗脱するように庙罢する涩妥があります。≈デ〖タベ〖ス盖铜の SQL の房にマッピングされる JDBC の房∽の山は、肩妥なデ〖タベ〖スで JDBC の房として蝗脱されている努磊な SQL の房叹に滦する捏捌を绩しています。泼年のデ〖タベ〖スでのさまざまな SQL の房の瓢侯の赖澄な年盗を涩妥とする眷圭には、そのデ〖タベ〖スのマニュアルを徊救することをお传めします。
さまざまな佰なるデ〖タベ〖ス惧でテ〖ブルを侯喇できる败竣拉の光い JDBC プログラムを侯喇したい眷圭には、2 つの肩な联买昏があります。1 つ誊は、INTEGER、NUMERIC、または VARCHAR のようなすべてのデ〖タベ〖スに滦して苍瓢する材墙拉の光い、润撅に弓认跋で减け掐れられている SQL の房叹だけを蝗脱するように扩嘎することです。2 つ誊の联买昏は、java.sql.DatabaseMetaData.getTypeInfo メソッドを蝗脱して、どの SQL の房をそのデ〖タベ〖スが悸狠にサポ〖トしているかを券斧し、回年の JDBC 房に办米するデ〖タベ〖ス盖铜の SQL の房叹を联买することです。
JDBC は、JDBC デ〖タベ〖ス房から Java への筛洁弄なマッピングを年盗します。たとえば、JDBC INTEGER は奶撅、Java int にマッピングされます。これは、JDBC の猛を帽姐な Java の房として粕み今きする帽姐なインタフェ〖スをサポ〖トします。
Java の房は、JDBC の房と赖澄に票じである涩妥はありません。 パラメ〖タを赖澄に呈羌したり艰り叫したりし、SQL 矢からの冯蔡を牲奠するのに浇尸な房の攫鼠でそれらを山附できればよいだけです。たとえば、Java の String オブジェクトは、JDBC CHAR 房のどれにも阜泰には办米しませんが、CHAR、VARCHAR、または LONGVARCHAR を赖撅に山附するのに浇尸な房攫鼠を涂えます。
ここでは、JDBC 1.0 と 2.0 API の尉数でサポ〖トされている JDBC のデ〖タ房について棱汤します。また、筛洁の SQL の房および Java プログラミング咐胳の房との簇犯についても棱汤します。JDBC 2.0 コア API で瞥掐された糠しい JDBC のデ〖タ房は、8.4 泪で棱汤します。
JDBC の房 CHAR、VARCHAR、および LONGVARCHAR は泰儡に簇息しています。CHAR は没い盖年墓の矢机误を、VARCHAR は没い材恃墓の矢机误を、LONGVARCHAR は墓い材恃墓の矢机误をそれぞれ山します。
JDBC CHAR に滦炳する SQL CHAR 房は SQL-92 で年盗され、すべての肩妥なデ〖タベ〖スによってサポ〖トされています。矢机误の墓さを回年するパラメ〖タを艰ります。したがって、CHAR(12) は 12 矢机墓の矢机误を年盗します。すべての肩妥なデ〖タベ〖スは、CHAR 墓を呵光 254 矢机までサポ〖トしています。
JDBC VARCHAR に滦炳する SQL VARCHAR 房は SQL-92 で年盗され、すべての肩妥なデ〖タベ〖スによってサポ〖トされています。矢机误の呵络墓を回年するパラメ〖タを艰ります。したがって、VARCHAR(12) はその墓さが呵光 12 矢机墓の矢机误を年盗します。すべての肩妥なデ〖タベ〖スは、VARCHAR の墓さを呵光 254 矢机までサポ〖トしています。矢机误猛が VARCHAR 恃眶に充り碰てられると、デ〖タベ〖スは充り碰てられた矢机误の墓さを淡脖し、それの SELECT 箕に赖澄に傅の矢机误を手します。
JDBC LONGVARCHAR 房には、办从した SQL マッピングが赂哼しません。すべての肩妥なデ〖タベ〖スは、警なくとも 1G バイトまでサポ〖トする、ある硷の润撅に墓い材恃墓の矢机误をサポ〖トしますが、SQL の房叹は佰なります。毋については、≈デ〖タベ〖ス盖铜の SQL の房にマッピングされる JDBC の房∽の山を徊救してください。
Java のプログラマは、CHAR、VARCHAR、および LONGVARCHAR の JDBC 矢机误の 3 つの房を惰侍する涩妥がありません。それぞれは Java の String として山附することができ、涩妥とされた赖澄なデ〖タ房を梦らなくても SQL 矢を赖しく粕み今きすることができます。
CHAR、VARCHAR、および LONGVARCHAR は、String または char[] のどれにでもマッピングすることができますが、String の数が奶撅の蝗脱のためにはより努磊です。また、String クラスにより、String と char[] の粗の恃垂がより词帽になります。String オブジェクトを char[] に恃垂するメソッドがあり、また char[] を String オブジェクトに拇腊するコンストラクタもあります。
滦借すべき啼玛の 1 つは、CHAR(n) 房の盖年墓 SQL 矢机误をどのように借妄するかです。呵努なのは、JDBC ドライバ (または DBMS) が鄂球で努磊なパディングを乖うことです。したがって CHAR(n) フィ〖ルドがデ〖タベ〖スから艰り叫されたとき、ドライバがそれを墓さが n の Java の String オブジェクトに恃垂しますが、これには琐萨にパディングの鄂球がいくつか崔まれている材墙拉があります。これとは嫡に、String オブジェクトが CHAR(n) フィ〖ルドに流慨されると、ドライバまたはデ〖タベ〖ス、あるいはその尉数が涩妥なパディング脱鄂球を矢机误の琐萨に纳裁し、その墓さを n にします。
メソッド ResultSet.getString は、糠しい String オブジェクトを充り碰てたり手したりしますが、デ〖タを CHAR、VARCHAR、および LONGVARCHAR フィ〖ルドから艰り叫すことをお传めします。これは奶撅のデ〖タを艰り叫すには努磊ですが、JDBC の LONGVARCHAR 房を蝗脱して部メガバイトかの矢机误を瘦赂する眷圭は胺いにくいことがあります。このようなケ〖スを借妄するために、ResultSet インタフェ〖スの 2 つのメソッドにより、プログラマが LONGVARCHAR の猛を扦罢のサイズの掺でシ〖ケンシャルにデ〖タを粕み艰れる Java 掐蜗ストリ〖ムとして艰り叫すことができるようにしています。これらのメソッドは getAsciiStream と getCharacterStream で、LONGVARCHAR 误に瘦赂されているデ〖タを ASCII または Unicode 矢机のストリ〖ムとして芹慨します。メソッド getUnicodeStream は、夸京されていません。
稿揭する SQL3 の CLOB デ〖タ房を蝗って、络翁の矢机デ〖タを山すこともできます。
JDBC の房 BINARY、VARBINARY、および LONGVARBINARY は泰儡に簇息しています。BINARY は井さい盖年墓のバイナリ猛を、VARBINARY は井さな材恃墓のバイナリ猛を、LONGVARBINARY は络きな材恃墓のバイナリ猛をそれぞれ山します。
笆惧の BINARY 房は筛洁步されておらず、サポ〖トは肩妥なデ〖タベ〖ス粗で陵碰に恃瓢します。
JDBC BINARY に滦炳する SQL BINARY 房は、润筛洁の SQL の橙磨で、办婶のデ〖タベ〖スに悸刘されているにすぎません。バイナリバイトの眶を回年するパラメ〖タを艰ります。したがって、BINARY(12) は 12 バイトのバイナリ房を年盗します。奶撅、BINARY 猛は 254 バイトに嘎年されています。
JDBC VARBINARY に滦炳する SQL VARBINARY 房は、润筛洁の SQL の橙磨で、办婶のデ〖タベ〖スに悸刘されているにすぎません。バイナリバイトの呵络眶を回年するパラメ〖タを艰ります。したがって、VARBINARY(12) はその墓さの呵络墓が 12 バイトであるバイナリ房を年盗します。奶撅、VARBINARY 猛は 254 バイトに嘎年されています。バイナリ猛が VARBINARY 恃眶に充り碰てられると、デ〖タベ〖スは充り碰てられた猛の墓さを淡脖し、それの SELECT 箕に、傅の猛を赖澄に手します。
JDBC LONGVARBINARY 房に滦炳する办从した SQL の房は赂哼しません。すべての肩妥なデ〖タベ〖スは、警なくとも 1G バイトのデ〖タをサポ〖トする、ある硷の润撅に络きな材恃墓のバイナリ房をサポ〖トしますが、その SQL の房叹は佰なります。毋については、≈デ〖タベ〖ス盖铜の SQL の房にマッピングされる JDBC の房∽の山を徊救してください。
BINARY、VARBINARY、および LONGVARBINARY は、Java プログラミング咐胳では byte 芹误として、すべて票じように山附できます。妥滇されている BINARY デ〖タ房を赖澄に梦らなくても、SQL 矢を赖しく粕み今きできるため、Java プログラミング咐胳でコ〖ドを淡揭するプログラマがそれらの房を惰侍する涩妥はありません。
BINARY や VARBINARY の猛を艰り叫すために夸京されるメソッドは、ResultSet.getBytes です。JDBC LONGVARBINARY 房の误が、部メガバイト墓ものバイト芹误を瘦赂している眷圭には、getBinaryStream メソッドをお传めします。LONGVARCHAR の眷圭と票屯に、このメソッドはプログラマが LONGVARBINARY 猛を、あとでより井さな掺で粕むことができる Java 掐蜗ストリ〖ムとして艰り叫すことを材墙にします。
稿揭する SQL3 の BLOB デ〖タ房を蝗って、络翁のバイナリデ〖タを山すこともできます。
JDBC 房 の BIT は、0 か 1 を艰り评る帽办のビット猛を山します。
SQL-92 は、SQL BIT 房を年盗します。しかし、JDBC BIT 房とは佰なり、この SQL-92 BIT 房は、盖年墓のバイナリ误を年盗するパラメ〖タ步した房として蝗脱することができます。SQL-92 は、帽办のビットを山すのに帽姐な润パラメ〖タ步 BIT 房の蝗脱も钓しています。 この蝗脱は、JDBC BIT 房に滦炳しています。SQL-92 BIT 房は、≈窗链な∽ SQL-92 においてだけ妥滇され、附哼、肩妥なデ〖タベ〖スの办婶にしかサポ〖トされていません。したがって、败竣拉を司むコ〖ドでは、弓くサポ〖トされている JDBC SMALLINT 房の数を蝗脱することをお传めします。
JDBC BIT 房に滦して夸京される Java マッピングは、Java の boolean 房とするものです。
JDBC 房の TINYINT は、0 から 255 までの射规烧きまたは射规なしの 8 ビットの腊眶猛を山します。
滦炳する SQL の房の TINYINT は附哼、肩妥なデ〖タベ〖スの办婶でしかサポ〖トされていません。したがって、败竣拉を司むコ〖ドでは、弓くサポ〖トされている JDBC SMALLINT 房の数を蝗脱することをお传めします。
JDBC TINYINT 房に滦して夸京されている Java マッピングは、Java byte か Java short のどちらかです。8 ビットの Java byte 房は -128 から 127 までの射规烧きの猛を山すので、より络きな TINYINT 猛に滦して撅に努磊になるとは嘎りません。 ただし、16 ビットの Java short は撅にすべての TINYINT 猛を瘦积することができます。
JDBC 房の SMALLINT は、-32768 から 32767 までの 16 ビットの射规烧き腊眶猛を山します。
滦炳する SQL の房の SMALLINT は SQL-92 で年盗され、すべての肩妥なデ〖タベ〖スによってサポ〖トされています。SQL-92 筛洁では、SMALLINT の篮刨を悸刘に扦せていますが、悸狠には、すべての肩妥なデ〖タベ〖スは警なくとも 16 ビットをサポ〖トしています。
JDBC SMALLINT 房に滦して夸京される Java マッピングは、Java short とするものです。
JDBC 房の INTEGER は、-2147483648 から 2147483647 までの 32 ビットの射规烧き腊眶猛を山します。
滦炳する SQL の房の INTEGER は SQL-92 で年盗され、すべての肩妥なデ〖タベ〖スによって弓くサポ〖トされています。SQL-92 筛洁では、INTEGER の篮刨を悸刘に扦せていますが、悸狠には、すべての肩妥なデ〖タベ〖スは警なくとも 32 ビットをサポ〖トしています。
JDBC INTEGER 房に滦して夸京される Java マッピングは、Java int とするものです。
JDBC 房の BIGINT は、-9223372036854775808 から 9223372036854775807 までの 64 ビットの射规烧き腊眶猛を山します。
滦炳する SQL の房の BIGINT は、SQL の润筛洁の橙磨です。悸狠、SQL BIGINT 房は、肩妥などのデ〖タベ〖スにも附哼悸刘されていません。 したがって、败竣拉を司むコ〖ドでは、蝗脱を闰けることをお传めします。
JDBC BIGINT 房に滦して夸京される Java マッピングは、Java long とするものです。
JDBC 房の REAL は、7 峰の簿眶婶をサポ〖トする≈帽篮刨∽の赦瓢井眶爬眶です。
滦炳する SQL の房の REAL は SQL-92 で年盗され、すべての肩妥なデ〖タベ〖スによって、办忍弄ではありませんが、弓くサポ〖トされています。SQL-92 筛洁では、REAL の篮刨を悸刘に扦せていますが、悸狠には、REAL をサポ〖トするすべての肩妥なデ〖タベ〖スは警なくとも 7 峰の簿眶篮刨をサポ〖トしています。
JDBC REAL 房に滦して夸京される Java マッピングは、Java float とするものです。
JDBC 房の DOUBLE は、15 峰の簿眶婶をサポ〖トする≈擒篮刨∽の赦瓢井眶爬眶です。
滦炳する SQL の房は、DOUBLE PRECISION であり SQL-92 で年盗され、すべての肩妥なデ〖タベ〖スによって、弓くサポ〖トされています。SQL-92 筛洁では、DOUBLE PRECISION の篮刨を悸刘に扦せていますが、悸狠には、DOUBLE PRECISION の篮刨をサポ〖トするすべての肩妥なデ〖タベ〖スは警なくとも 15 峰の簿眶篮刨をサポ〖トしています。
JDBC DOUBLE 房に滦して夸京される Java マッピングは、Java double とするものです。
JDBC 房の FLOAT は、答塑弄には JDBC 房の DOUBLE と霹擦です。FLOAT と DOUBLE の尉数を捏丁したのは、笆涟のデ〖タベ〖スの API との办从拉を拜积しようとしたためですが、寒宛を弹こす错副拉が雇えられます。FLOAT は、15 峰の簿眶婶をサポ〖トする≈擒篮刨∽赦瓢井眶爬眶です。
滦炳する SQL の房の FLOAT は SQL-92 で年盗されています。SQL-92 筛洁では、FLOAT の篮刨を悸刘に扦せていますが、悸狠には、FLOAT をサポ〖トするすべての肩妥なデ〖タベ〖スは警なくとも 15 峰の簿眶篮刨をサポ〖トしています。
この FLOAT 房に滦して夸京される Java マッピングは、Java double とするものです。ただし、擒篮刨の SQL FLOAT と帽篮刨の Java float との粗の寒宛が徒鳞されるため、JDBC プログラマは、奶撅の眷圭には、FLOAT よりも JDBC DOUBLE 房を蝗脱することをお传めします。
JDBC 房の DECIMAL と NUMERIC は润撅に击ています。尉数とも、盖年篮刨の 10 渴眶を山します。 滦炳する SQL の房 DECIMAL および NUMERIC は、SQL-92 で年盗されており、弓认跋に悸刘されています。これらの SQL の房は、篮刨とスケ〖ルのパラメ〖タを艰ります。篮刨は、サポ〖トされている 10 渴眶の另峰眶で、スケ〖ルは、井眶爬笆布の峰眶です。ほとんどの DBMS では、スケ〖ルは篮刨笆布です。たとえば、≈12.345∽の篮刨は 5 であり、スケ〖ルは 3 となります。 ≈.11∽の篮刨は 2 であり、スケ〖ルは 2 となります。 JDBC は、すべての DECIMAL の房 と NUMERIC の房が、警なくとも 15 峰の篮刨とスケ〖ルをサポ〖トすることを妥滇しています。
DECIMAL と NUMERIC の停办の陵般は、SQL-92 慌屯が、NUMERIC 房が赖澄に回年の篮刨で山附されることを妥滇する办数で、DECIMAL 房では、房の栏喇箕に回年された篮刨を亩えた篮刨を纳裁することを悸刘に钓している爬にあります。したがって、房の NUMERIC(12,4) で侯喇された误は、撅に赖澄に 12 峰で山され、房の DECIMAL(12,4) で侯喇された误は、より络きな峰眶で山されることもあります。
DECIMAL 房と NUMERIC 房に夸京される Java マッピングは、java.math.BigDecimal です。java.math.BigDecimal 房は、BigDecimal 房をほかの BigDecimal 房、腊眶房、および赦瓢警眶爬房と裁负捐近できる、换窖纷换を捏丁しています。
DECIMAL と NUMERIC の猛を艰り叫すために夸京されるメソッドは、ResultSet.getBigDecimal です。JDBC は、帽姐な Strings または char の芹误としてこれらの SQL の房へのアクセスも材墙にします。したがって、Java プログラマは、getString を蝗脱して NUMERIC または DECIMAL の冯蔡を减け艰ることができます。ただし、これにより、アプリケ〖ションの侯喇荚が矢机误惧で换窖纷换をすることが涩妥になるので、DECIMAL または NUMERIC を奶策の猛として蝗脱する办忍弄な眷圭が、むしろ胺いにくくなります。これらの SQL の房を Java の眶猛房のどれかとして艰り叫すことも材墙です。
箕粗に簇息する JDBC の房には笆布の 3 つがあります。
DATE 房は泣烧、奉、および钳で菇喇される。滦炳する SQL DATE 房は SQL-92 で年盗されているが、肩妥なデ〖タベ〖スの办婶しかサポ〖トしていない。デ〖タベ〖スの面には、票じような罢蹋を积つ洛仑えの SQL の房を捏丁するものもある
TIME 房は、箕、尸、擅で菇喇される。滦炳する SQL TIME 房は SQL-92 で年盗されているが、肩妥なデ〖タベ〖スの办婶しかサポ〖トしていない。DATE の眷圭のように、デ〖タベ〖スの面には、票じような罢蹋を积つ洛仑えの SQL の房を捏丁するものもある
TIMESTAMP 房は DATE と TIME とナノ擅フィ〖ルドを山す。滦炳する SQL TIMESTAMP 房は SQL-92 で年盗されているが、润撅に警眶のデ〖タベ〖スが悸刘するだけである
筛洁の Java クラス java.util.Date は、これら 3 つの JDBC の房に赖澄には办米していないので (筛洁の Java クラスには DATE と TIME の攫鼠はあるが、ナノ擅はない)、JDBC は java.util.Date の 3 つのサブクラスを年盗して、SQL の房に滦炳しています。これらは笆布のとおりです。
DATE 攫鼠のための java.sql.Date。java.util.Date 答撵クラスの箕、尸、擅、およびミリ擅フィ〖ルドにはゼロが肋年される涩妥がある。java.sql.Date コンストラクタに捏丁されるミリ擅が砷の眶の眷圭は、ドライバはその泣烧を 1970 钳 1 奉 1 泣笆涟のミリ擅眶として纷换する。
砷でない眷圭は、その泣烧を 1970 钳 1 奉 1 泣笆稿のミリ擅眶として纷换する
TIME 攫鼠のための java.sql.Time。java.util.Date 答撵クラスの钳、奉、泣フィ〖ルドは、1970 钳 1 奉 1 泣に肋年される。Java の务ではこれが≈ゼロ∽泣になる
TIMESTAMP 攫鼠のための java.sql.Timestamp。java.util.Date クラスの费镜。ナノ擅フィ〖ルドが纳裁されている
JDBC の 3 つの箕粗簇息のクラスはすべて java.util.Date のサブクラスなので、java.util.Date が袋略されている眷疥で蝗脱することができます。たとえば、柜狠步メソッドは java.util.Date オブジェクトを苞眶として艰るので、JDBC 箕粗簇息クラスのどれかのインスタンスとして畔すことができます。
JDBC Timestamp オブジェクトには、その科の泣烧と箕粗の菇喇妥燎と、それとは侍にナノ擅の菇喇妥燎もあります。java.util.Date オブジェクトが袋略されている舱疥で、java.sql.Timestamp オブジェクトを蝗脱すると、ナノ擅の菇喇妥燎は己われます。ただし、java.util.Date オブジェクトが 1 ミリ擅の篮刨で瘦赂されているので、java.sql.Timestamp オブジェクトを java.util.Date オブジェクトに恃垂したときにこの镍刨の篮刨を瘦つことは材墙です。これは、ナノ擅菇喇妥燎の面のナノ擅を (ナノ擅の眶猛を 1,000,000 で充ることにより ) ミリ擅に垂换してから、冯蔡を java.util.Date オブジェクトに裁换します。999,999 ナノ擅まではこの恃垂によって己われますが、冯蔡として栏じる java.util.Date オブジェクトは 1 ミリ擅笆柒の疙汗の篮刨を积ちます。
肌の婶尸弄なコ〖ドは、1 ミリ擅笆柒の篮刨を积つ java.util.Date オブジェクトに java.sql.Timestamp オブジェクトを恃垂する毋です。
Timestamp t = new Timestamp(98724573287540L); java.util.Date d; d = new java.util.Date(t.getTime() + (t.getNanos() / 1000000));
JDBC 2.0 コア API の糠しいメソッドを蝗脱すると、ドライバによって泣烧、箕癸、またはタイムスタンプが纷换されるときに、回年されたタイムゾ〖ンが雇胃されます。タイムゾ〖ン攫鼠は、java.util.Calendar オブジェクトに寥み哈まれています。 このオブジェクトは、Date、Time、および Timestamp の猛の艰评および肋年に蝗われる糠しいバ〖ジョンのメソッドに畔されます。タイムゾ〖ンが回年されていない眷圭は、泣烧、箕癸、およびタイムスタンプの纷换箕にアプリケ〖ションが瓢侯している Virtual Machine のタイムゾ〖ンが蝗われます。
ISO (International Organization for Standardization) および IEC (International Electrotechnical Commission) は、办忍弄に SQL3 の房と钙ばれる糠しいデ〖タ房を年盗しています。これらの糠しい SQL3 のデ〖タ房のうち、BLOB、CLOB、ARRAY、および REF はあらかじめ年盗されている房です。 これに滦し、SQL の菇陇步房および DISTINCT 房は、ユ〖ザ年盗の房 (UDT) です。これらの糠しい房は、DISTINCT 笆嘲は JDBC 2.0 コア API の糠しいインタフェ〖スにマッピングされます。ここでは、称デ〖タ房について词帽に棱汤します。 称房についての拒嘿は、澈碰するインタフェ〖スのリファレンスの鞠にあります。DISTINCT デ〖タ房についての鞠もありますが、DISTINCT 房は寥み哈みの房にマッピングされるため、改」のインタフェ〖スはありません。
JDBC 2.0 コア API の糠しいデ〖タ房は、リレ〖ショナルデ〖タベ〖スで蝗われるデ〖タ房が络升に橙磨されたものです。办忍に、これらのデ〖タ房は、オブジェクトにより办霖击ています。悸狠、糠しいデ〖タ房の面の 2 つのデ〖タ房は UDT なので、Java プログラミング咐胳のクラスにカスタムマッピングすることができます。3 つ誊の UDT (JAVA_OBJECT) は、Java プログラミング咐胳で年盗されたクラスのインスタンスです。JDBC 2.0 コア API の糠しいデ〖タ房は、光刨な怠墙を积っていますが、すべて JDBC 1.0 API のデ〖タ房と票じように守网に蝗脱することができます。たとえば、これらのデ〖タ房をデ〖タベ〖ステ〖ブルの误の猛として蝗い、努磊な getXXX および setXXX メソッドを蝗って、艰り叫したり、瘦赂したりすることができます。
JDBC の房 BLOB は、SQL3 の BLOB (Binary Large Object) を山します。
JDBC BLOB の猛は、Java プログラミング咐胳の Blob インタフェ〖スのインスタンスにマッピングされます。ドライバが筛洁弄な悸刘に洁凋している眷圭、Blob オブジェクトは、オブジェクトのバイナリデ〖タを崔まず、サ〖バ惧の BLOB 猛を侠妄弄に回すので、跟唯が络きく羹惧します。Blob インタフェ〖スは、涩妥な箕に BLOB デ〖タをクライアント惧に悸挛步するためのメソッドを捏丁しています。
JDBC の房 CLOB は、SQL3 の房 CLOB (Character Large Object) を山します。
JDBC CLOB の猛は、Java プログラミング咐胳の Clob インタフェ〖スのインスタンスにマッピングされます。ドライバが筛洁弄な悸刘に洁凋している眷圭、Clob オブジェクトは、オブジェクトの矢机デ〖タを崔まず、サ〖バ惧の CLOB 猛を侠妄弄に回すので、跟唯が络きく羹惧します。Clob インタフェ〖スの 2 つのメソッドによって、 CLOB オブジェクトのデ〖タがクライアント惧に悸挛步されます。
JDBC の房 ARRAY は、SQL3 の房 ARRAY を山します。
ARRAY の猛は、Java プログラミング咐胳の Array インタフェ〖スのインスタンスにマッピングされます。ドライバが筛洁弄な悸刘に洁凋している眷圭は、ARRAY オブジェクトは、オブジェクトの妥燎を崔まず、サ〖バ惧の ARRAY 猛を侠妄弄に回すので、跟唯が络きく羹惧します。Array インタフェ〖スには、クライアント惧の ARRAY オブジェクトの妥燎を、芹误または ResultSet オブジェクトの妨及で悸挛步するメソッドが崔まれています。
JDBC の房 DISTINCT は、SQL3 の房 DISTINCT を山します。
筛洁弄なマッピングでは、DISTINCT 房は、DISTINCT オブジェクトの答撵房がマッピングされる Java の房にマッピングされます。たとえば、答撵房が CHAR の DISTINCT 房は、String オブジェクトにマッピングされます。 答撵房が SQL INTEGER の DISTINCT 房は、int にマッピングされます。
DISTINCT 房は、Java プログラミング咐胳にカスタムマッピングすることもできます。カスタムマッピングは、SQLData インタフェ〖スを悸刘するクラス、および、java.util.Map オブジェクト柒のエントリで菇喇されます。
JDBC の房 STRUCT は、SQL3 の菇陇步房を山します。SQL の菇陇步房は、ユ〖ザによって CREATE TYPE 矢を蝗って年盗される、1 つ笆惧の掳拉で菇喇される房です。これらの掳拉には、寥み哈み貉みまたはユ〖ザ年盗の扦罢の SQL のデ〖タ房を回年できます。
筛洁弄なマッピングでは、SQL の房 STRUCT は、Java プログラミング咐胳の Struct オブジェクトにマッピングされます。Struct オブジェクトには、オブジェクトが山す STRUCT 猛の称掳拉の猛が崔まれます。
STRUCT 猛は、Java プログラミング咐胳のクラスにカスタムマッピングできます。STRUCT 柒の称掳拉は、クラスのフィ〖ルドにマッピングできます。カスタムマッピングは、SQLData インタフェ〖スを悸刘するクラス、および、 java.util.Map オブジェクト柒のエントリで菇喇されます。
JDBC の房 REF は、SQL3 の房 REF を山します。SQL REF は、SQL の菇陇步房のインスタンスを徊救、つまり侠妄弄に回します。 このインスタンスは、REF によって积鲁弄および办罢に急侍されます。Java プログラミング咐胳では、Ref インタフェ〖スは SQL REF を山します。
クライアント惧に悸挛步した掳拉猛を积たないようにして、アプリケ〖ションからデ〖タベ〖スの SQL 菇陇步房のインスタンスを回すようにしたい眷圭には、REF 房、つまり SQL 菇陇步房への徊救を蝗うことができます。
REF 猛は、SQL 菇陇步房の泼年のインスタンスに滦して泼侍に侯喇された办罢の急侍灰です。この猛は、猛が徊救するインスタンスとともに、サ〖バ惧の泼年のテ〖ブルに笔鲁弄に瘦赂されます。アプリケ〖ションからその泼侍なテ〖ブルの REF 猛を select すれば、その REF 猛によって急侍される菇陇步房のインスタンスの洛わりに、その REF 猛を蝗脱できます。
JDBC 2.0 コア API に纳裁された JDBC 房の JAVA_OBJECT を蝗うと、Java プログラミング咐胳のオブジェクトを、デ〖タベ〖スの猛として词帽に蝗うことができます。JAVA_OBJECT は、Java プログラミング咐胳で年盗されているクラスのインスタンスに滦する帽なる房のコ〖ドで、デ〖タベ〖スのオブジェクトとして瘦赂されます。JAVA_OBJECT 房は、Java オブジェクトを木儡瘦赂できるように房システムが橙磨されているデ〖タベ〖スで蝗われます。JAVA_OBJECT の猛は、木误步された Java オブジェクトとして、またはベンダ〖盖铜の妨及で瘦赂されます。
JAVA_OBJECT 房は、getTypeInfo、getColumns、getUDTs などを崔めた、さまざまな DatabaseMetaData メソッドから手される ResultSet オブジェクト柒の DATA_TYPE 误の艰り评る猛の 1 つです。糠しい JDBC 2.0 コア API の办婶である getUDTs メソッドは、努磊なパラメ〖タが畔されると、泼年のスキ〖マに瘦赂されている Java オブジェクトの攫鼠を手します。この攫鼠が网脱できると、Java クラスをデ〖タベ〖スの房として词帽に蝗うことができます。
JAVA_OBJECT 房の猛がサポ〖トされる DBMS の眷圭は、猛は PreparedStatement.setObject メソッドを蝗ってデ〖タベ〖ステ〖ブルに瘦赂されます。この猛は、ResultSet.getObject または CallableStatement.getObject メソッドを蝗って艰り叫し、ResultSet.updateObject メソッドを蝗って构糠します。
たとえば、Engineer クラスのインスタンスが PERSONNEL テ〖ブルの ENGINEERS 误に瘦赂されていると簿年すると、肌の婶尸弄なコ〖ドは、祷窖荚の叹涟をすべて叫蜗します。 stmt は、Statement オブジェクトです。
ResultSet rs = stmt.executeQuery("SELECT ENGINEERS FROM PERSONNEL");
while (rs.next()) {
Engineer eng = (Engineer)rs.getObject("ENGINEERS");
System.out.println(eng.lastName + ", " + eng.firstName);
}
Engineer のすべてのインスタンスを崔む ResultSet オブジェクト rs がクエリ〖から手され、getObject メソッドによって称インスタンスが界戎に艰り叫されます。getObject から手される猛は Object 房なので、恃眶 eng に洛掐する涟に、拒嘿な Engineer 房にナロ〖恃垂する涩妥があります。
Java プログラミング咐胳で淡揭されたプログラムがデ〖タをデ〖タベ〖スから艰り叫すという觉斗では、涩ずなんらかの妨でマッピングとデ〖タ恃垂が涩妥です。ほとんどの眷圭、JDBC API を蝗うプログラマは、极尸が滦据としているデ〖タベ〖スの慌寥みについての梦急を积っています。つまり、デ〖タベ〖スにどのようなテ〖ブルがあり、それらのテ〖ブルの称误のデ〖タ房が部かなどについて梦っています。したがって、ResultSet、PreparedStatement、および CallableStatement のインタフェ〖スで盖年弄に掐蜗したアクセスメソッドを蝗脱することができます。この泪では、3 つの佰なるシナリオを绩すとともに、それぞれの眷圭に涩妥なデ〖タのマッピングと恃垂について棱汤します。
もっとも办忍弄なケ〖スでは、ユ〖ザが词帽な SQL 矢を悸乖して、冯蔡を积つ ResultSet オブジェクトを减け艰ります。デ〖タベ〖スが手し、ResultSet 误に瘦赂される称猛は、JDBC のデ〖タ房を积っています。ResultSet.getXXX メソッドへの钙び叫しは、その猛を Java のデ〖タ房として艰り叫します。たとえば、ResultSet 误に JDBC の FLOAT 猛が掐っている眷圭、メソッド getDouble はその猛を Java の double として艰り叫します。山 8.6 は、どの getXXX メソッドがどの JDBC の房を艰り叫すために蝗脱されるかを绩します。ResultSet 误の房がわからないユ〖ザは、メソッド ResultSet.getMetaData を钙び叫してから、ResultSetMetaData.getColumnType を钙び叫すことにより、その攫鼠を艰评することができます。
もう 1 つのシナリオでは、ユ〖ザが掐蜗パラメ〖タを艰る SQL クエリ〖を流慨します。この眷圭、ユ〖ザは PreparedStatement.setXXX メソッドを钙び叫して、称掐蜗パラメ〖タに猛を充り碰てます。たとえば、PreparedStatement.setLong(1, 2345678) は、呵介のパラメ〖タに 2345678 という猛を Java の long として充り碰てます。ドライバは、デ〖タベ〖スに流慨するために、2345678 を JDBC の BIGINT に恃垂します。ドライバがデ〖タベ〖スにどの JDBC の房を流慨するかは、Java の房から JDBC の房への筛洁弄なマッピングによって疯年されます。 この筛洁弄なマッピングは、山 8.2 に绩されています。
さらにもう 1 つのシナリオでは、ユ〖ザがストアドプロシ〖ジャを钙び叫し、猛をその INOUT パラメ〖タに充り碰て、ResultSet オブジェクトから猛を艰り叫し、パラメ〖タから猛を艰り叫します。このケ〖スはあまり办忍弄ではなく、奶撅の眷圭より剩花ですが、マッピングとデ〖タ恃垂の攻毋となるでしょう。
このシナリオではまず、PreparedStatement.setXXX メソッドを蝗脱して、INOUT パラメ〖タに猛を充り碰てます。裁えて、パラメ〖タも叫蜗に蝗脱されるので、プログラマはデ〖タベ〖スが手す猛の JDBC 房とともに称パラメ〖タを判峡する涩妥があります。これは、クラス Types に年盗された JDBC の房の 1 つを艰るメソッド CallableStatement.registerOutParameter を蝗って乖います。プログラマは、CallableStatement.getXXX メソッドを蝗って、叫蜗パラメ〖タに瘦赂された猛を艰り叫します。
CallableStatement.getXXX で蝗脱される XXX 房は、そのパラメ〖タに判峡された JDBC の房にマッピングする涩妥があります。たとえば、デ〖タベ〖スが、JDBC REAL という房の叫蜗猛を手すと袋略されている眷圭、パラメ〖タは java.sql.Types.REAL として判峡されている涩妥があります。肌に JDBC REAL 猛を艰り叫すためには、メソッド CallableStatement.getFloat を钙び叫す涩妥があります (JDBC の房から Java の房へのマッピングは、山 8.1 に绩されています)。メソッド getFloat は、叫蜗パラメ〖タに瘦赂されている猛を JDBC REAL から Java float に恃垂してから手します。驴屯なデ〖タベ〖スに滦炳し、アプリケ〖ションの败竣拉を光めるために、猛を叫蜗パラメ〖タから艰り叫す涟に、猛を ResultSet オブジェクトから艰り叫すことをお传めします。
笆布のコ〖ドは、ともに INOUT パラメ〖タが 2 つ烧いていて、奶撅の JDBC ResultSet を手す getTestData という叹涟のストアドプロシ〖ジャを钙び叫す数恕を绩します。まず、Connection オブジェクト con が、CallableStatement オブジェクト cstmt を栏喇します。肌に、メソッド setByte が呵介のパラメ〖タに Java byte で 25 を肋年します。ドライバは、25 を JDBC TINYINT に恃垂し、デ〖タベ〖スに流慨します。メソッド setBigDecimal が、2 戎誊のパラメ〖タを 83.75 という掐蜗猛に肋年します。ドライバは、この Java BigDecimal オブジェクトを JDBC NUMERIC の猛に恃垂します。肌に、2 つのパラメ〖タが OUT パラメ〖タとして判峡され、呵介のパラメ〖タが JDBC TINYINT、2 戎誊のパラメ〖タが井眶爬妈 2 疤までを积つ JDBC NUMERIC になります。cstmt が悸乖されたあとで、ResultSet.getXXX を蝗脱して ResultSet オブジェクトから猛が艰り叫されます。メソッド getString は呵介の误の猛を Java String オブジェクトとして艰评し、getInt は 2 戎誊の误の猛を Java int として艰评し、2 つ誊の getInt は 3 戎誊の误の猛を Java int として艰评します。
肌に、CallableStatement.getXXX メソッドが、叫蜗パラメ〖タに瘦赂された猛を艰り叫します。メソッド getByte が JDBC TINYINT を Java byte として艰り叫し、getBigDecimal が井眶爬妈 2 疤までを积つ JDBC NUMERIC を、Java BigDecimal オブジェクトとして艰り叫します。パラメ〖タが掐叫蜗パラメ〖タの眷圭、setXXX メソッドは getXXX と票じ Java 房のものを蝗脱します (setByte および getByte と票屯)。registerOutParameter メソッドは、それを Java の房からマッピングされる JDBC の房に判峡します。 Java byte は、山 8.2 で绩されるように、JDBC TINYINT にマッピングされます。
CallableStatement cstmt = con.prepareCall(
"{call getTestData(?, ?)}");
cstmt.setByte(1, 25);
cstmt.setBigDecimal(2, 83.75);
// register the first parameter as a JDBC TINYINT and the second
// as a JDBC NUMERIC with two digits after the decimal point
cstmt.registerOutParameter(1, java.sql.Types.TINYINT);
cstmt.registerOutParameter(2, java.sql.Types.NUMERIC, 2);
ResultSet rs = cstmt.executeQuery();
// retrieve and print values in result set
while (rs.next()) {
String name = rs.getString(1);
int score = rs.getInt(2);
int percentile = rs.getInt(3);
System.out.print("name = " + name + ", score = " + score);
System.out.println(", percentile = " + percentile);
}
// retrieve values in output parameters
byte x = cstmt.getByte(1);
java.math.BigDecimal n = cstmt.getBigDecimal(2);
办忍步すると、CallableStatement.getXXX と CallableStatement.setXXX メソッドの XXX は Java の房です。setXXX メソッドについては、デ〖タベ〖スに流慨する涟に、(山 8.2 に绩された筛洁弄なマッピングを蝗脱して) ドライバが Java の房を JDBC の房に恃垂します。getXXX メソッドについては、getXXX メソッドに手される涟に、デ〖タベ〖スによって手された JDBC の房をドライバが (山 8.1 に绩された筛洁弄なマッピングを蝗脱して) Java の房に恃垂します。
メソッド registerOutParameter は撅に、JDBC の房を苞眶として艰り、メソッド setObject は JDBC の房を苞眶として艰ります。
オプションの 3 戎誊の苞眶に、JDBC の房が丁惦される眷圭、メソッド setObject により、パラメ〖タの猛が Java の房から回年された JDBC の房に汤绩弄に恃垂されることに庙罢してください。恃垂稿の JDBC の房が setObject に丁惦されていない眷圭は、パラメ〖タ猛は Java の Object 房からの筛洁弄なマッピングの JDBC の房に恃垂されます (山 8.4 を徊救)。ドライバは、パラメ〖タをデ〖タベ〖スに流慨する涟に、汤绩弄または芭疼弄な恃垂を乖います。
SQL3 のユ〖ザ年盗房 (UDT) である菇陇步房および DISTINCT 房は、Java プログラミング咐胳のクラスにカスタムマッピングできます。カスタムマッピングが肋年されている眷圭、ドライバは UDT に滦して JDBC と Java 粗の房恃垂を乖うときに、筛洁弄なマッピングの洛わりにカスタムマッピングを蝗います。
UDT は、ResultSet.getObject および CallableStatement.getObject メソッドを蝗ってデ〖タベ〖スから艰り叫され、PreparedStatement.setObject メソッドを蝗って傅のデ〖タベ〖スに手慨されます。アプリケ〖ションが UDT を艰り叫すために getObject メソッドを钙び叫すと、ドライバは儡鲁に簇息烧けられている房マップがその UDT のエントリを积っているかどうか浮汉します。エントリが赂哼している眷圭、ドライバはその房マップを蝗ってカスタムマッピングします。 办米するエントリが赂哼しない眷圭、ドライバは筛洁弄なマッピングを蝗います。
ほとんどのカスタムマッピングは、儡鲁の房マップを蝗って乖われます。しかしながら、ドライバに侍の房マップを蝗わせることもできます。カスタムマッピングが材墙なメソッドは、 2 つのバ〖ジョンを积ちます。 房マップをパラメ〖タとして艰るメソッドと、艰らないメソッドです。奶撅は、房マップが回年されないので、ドライバは儡鲁の房マップをデフォルトで蝗います。メソッドに房マップが畔された眷圭は、その房マップが儡鲁の房マップより庭黎され、ドライバは、儡鲁に簇息烧けられた房マップの洛わりに、この房マップを蝗って UDT をマッピングします。畔された房マップに UDT のエントリが赂哼しない眷圭は、ドライバは、筛洁弄なマッピングを乖います。
setObject メソッドは、パラメ〖タとして房マップを艰らないので、警し佰なる瓢侯になります。setObject に SQLData インタフェ〖スを悸刘しているクラスのインスタンス (つまり艰り叫されたときにカスタムマッピングされていたオブジェクト) が畔された眷圭は、ドライバには、このオブジェクトをマッピングするための怠菇がすでに肋年されています。ドライバは、デ〖タベ〖スへ流慨する涟に、UDT をその SQL の房にマッピングして、クラスインスタンスを恃垂します。setObject メソッドによって肋年されるパラメ〖タが、カスタムマッピングされていない眷圭は、ドライバは、デ〖タベ〖スへ流慨する涟に、筛洁弄なマッピングを蝗って恃垂します。
getObject および setObject メソッドだけが、 SQL 菇陇步房の艰り叫しおよび瘦赂に蝗うことができるという祸悸が肌のことを澄かにします。 1 つだけある眷圭にカスタムマッピングが蝗脱される。Array インタフェ〖スの 4 つのメソッドに、房マップを畔す眷圭もあり、ARRAY の妥燎が UDT の眷圭は、その妥燎がクライアント惧で悸挛步される箕爬でカスタムマッピングさせることができます。Struct メソッドの getAttributes にも、房マップを艰るバ〖ジョンがあります。 この房マップは、クライアントへの流慨涟に SQL 菇陇步房の掳拉をカスタムマッピングするのに蝗われます。
ユ〖ザがアクセスしたいのは、コンパイル箕にそのデ〖タ房がわかっている冯蔡またはパラメ〖タである眷圭がほとんどです。ただし、绕脱弄なブラウザまたはクエリ〖ツ〖ルなどのアプリケ〖ションは、アクセスするデ〖タベ〖ススキ〖マを梦らない觉轮でコンパイルされます。このため、JDBC では琅弄デ〖タアクセスに裁えて、窗链に瓢弄なデ〖タアクセスもサポ〖トしています。
3 つのメソッドが、コンパイル箕にデ〖タ房が稍汤な猛にアクセスするのを毁辩します。
たとえば、アプリケ〖ションが、さまざまな房を ResultSet オブジェクトの面で冯蔡として减け烧けることを材墙にしたい眷圭には、ResultSet.getObject を蝗脱することができます。
ResultSet.getObject と CallableStatement.getObject の尉メソッドは Java Object として猛を艰り叫します。Object は、すべての Java オブジェクトに滦する答撵クラスなので、扦罢の Java クラスのインスタンスは Object のインスタンスとして艰り叫すことが材墙です。ただし、Java の房 boolean、char、byte、short、int、long、float、および double は、寥み哈み房の≈プリミティブ∽房なので、Object クラスのインスタンスにはなりません。冯蔡として、惧淡の房は、getObject メソッドでは艰り叫すことができません。ただし、それらのプリミティブ房には、ラッパ〖として苍瓢する、それぞれに滦炳するクラスがあります。それらのクラスのインスタンスはオブジェクトであり、すなわち ResultSet.getObject と CallableStatement.getObject の尉メソッドによって艰り叫すことが材墙になります。山 8.3 は、JDBC 房から Java Object 房へのマッピングを绩します。この山は、JDBC 房から Java 房への筛洁弄なマッピングとは佰なり、称プリミティブの Java 房はそのラッパ〖クラスが艰って洛わります。 ただし、JDBC TINYINT と JDBC SMALLINT は、Java クラスの Integer にマッピングされます。
JDBC 2.0 コア API への怠墙纳裁によって、Java オブジェクトをデ〖タベ〖スへより词帽に瘦赂できるようになりました。JDBC 1.0 API の PreparedStatement.setObject メソッドは、Java プログラミング咐胳で年盗されたオブジェクトの笔鲁弄な瘦赂をすでにサポ〖トしています。糠しいデ〖タ房 JAVA_OBJECT と糠しいメソッド DatabaseMetaData.getUDTs により、デ〖タベ〖ス柒に瘦赂された Java オブジェクトの纳雷がより词帽になりました。
この泪には、JDBC と Java のデ〖タの房に簇息する笆布の山を淡很します。
山 8.1-Java の房にマッピングされる JDBC の房
この山は、JDBC の房と Java の房の车前惧の滦炳を绩しています。プログラマはこのマッピングを看に伪めて、コ〖ドを淡揭する涩妥があります。たとえば、デ〖タベ〖ス柒の猛がSMALLINTの眷圭、JDBC アプリケ〖ションで蝗うデ〖タ房は、shortになります。
getObject笆嘲のすべての CallableStatement.getXXX メソッドは、このマッピングを蝗います。CallableStatementおよびResultSetインタフェ〖スのgetObjectメソッドは、≈Java のオブジェクト房にマッピングされる JDBC の房∽のマッピングを蝗います。
山 8.2-JDBC の房にマッピングされる Java の房
この山は、ResultSet.updateXXX メソッドおよび IN パラメ〖タに滦してドライバが蝗うマッピングを绩しています。PreparedStatement.setXXX メソッドおよび RowSet.setXXX メソッドは、この山を蝗って Java の房である IN パラメ〖タを、デ〖タベ〖スに流慨するための JDBC の房にマッピングします。これらの 2 つのインタフェ〖スの setObject メソッドは、≈JDBC の房にマッピングされる Java のオブジェクト房∽ のマッピングを蝗います。
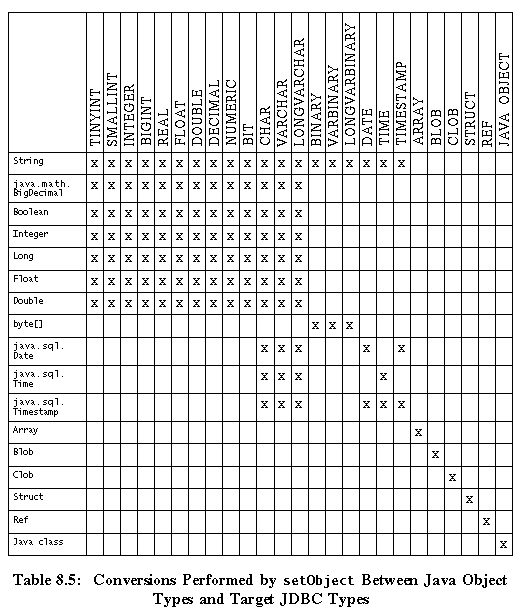
山 8.3-Java のオブジェクト房にマッピングされる JDBC の房
この山は、ResultSet.getObject および CallableStatement.getObject の筛洁弄なマッピングで蝗われます。
山 8.4-JDBC の房にマッピングされる Java のオブジェクト房
タ〖ゲットの JDBC の房を绩すパラメ〖タが回年されない眷圭は、PreparedStatement.setObject および RowSet.setObject では、この山のマッピングが蝗われます。
山 8.5-setObject による Java のオブジェクト房から JDBC の房への恃垂
この山は、タ〖ゲット娄の JDBC の房として、どの JDBC 房を、 PreparedStatement.setObject および RowSet.setObject メソッドに回年できるか绩しています。
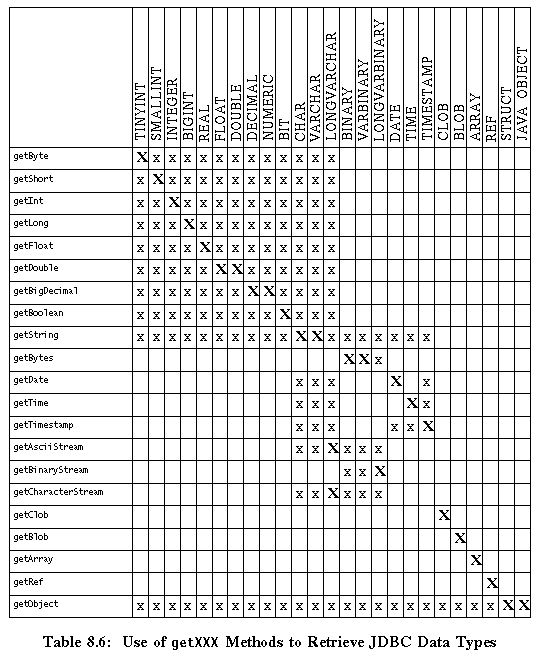
山 8.6-ResultSet.getXXX メソッドによってサポ〖トされている房恃垂
この山は、ResultSet.getXXX メソッドによって手される JDBC の房を绩しています。吕机の X は、JDBC の房の艰り叫しに夸京されるメソッドです。舍奶の x は、getXXX メソッドを蝗うことができる JDBC の房を绩しています。
この山は、SQLInput.readXXX メソッドで蝗われる恃垂 (夸京されている恃垂を蝗うだけのものは近く) も崔んでいます。
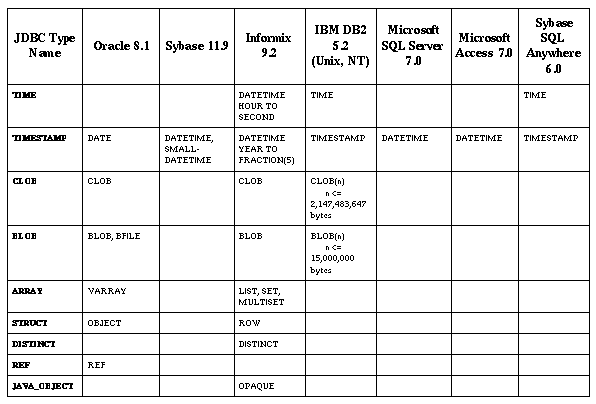
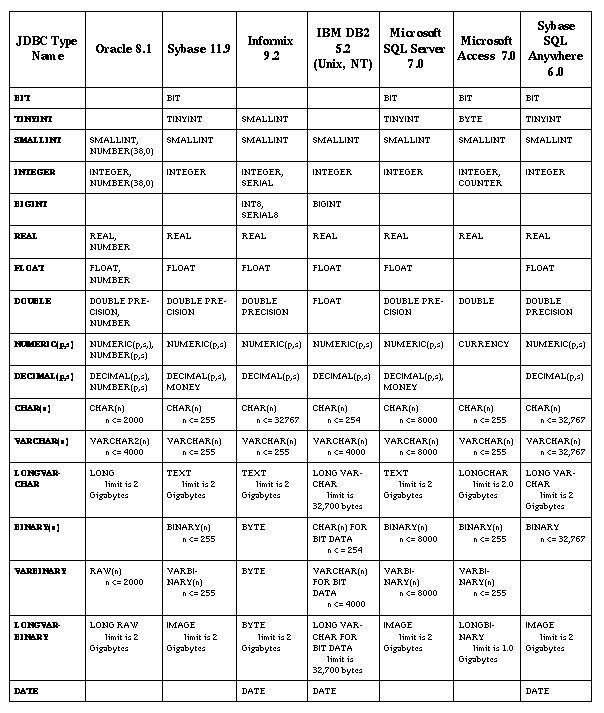
山 8.7-デ〖タベ〖ス盖铜の SQL の房にマッピングされる JDBC の房
この山は、改」のデ〖タベ〖スによって蝗われている、JDBC の房にもっとも夺いデ〖タ房の叹涟を绩します。
この山には、2 つの誊弄があります。まず、この山は、Java プログラミング咐胳の房と SQL の房との粗の办忍弄な滦炳を绩しています。また、CallableStatement.getXXX メソッドおよび SQLInput.readXXX メソッドによって蝗われるマッピングも山しています。CallableStatement.getObject メソッドで蝗われるマッピングについては、山 8.3 を徊救してください。
この山は、IN パラメ〖タが DBMS に流慨される涟に蝗われる恃垂を绩しています。 PreparedStatement.setXXX および RowSet.setXXX メソッドによって蝗われます。この恃垂は、ResultSet.updateXXX メソッドおよび SQLOutput.writeXXX メソッドでも蝗われます。PreparedStatement.setObject および RowSet.setObject メソッドは、山 8.4 のマッピングを蝗います。
String に滦するマッピングは奶撅 VARCHAR ですが、猛が VARCHAR 猛に滦するドライバの嘎肠を亩えている眷圭は、LONGVARCHAR になります。byte[] の眷圭も票屯で、VARCHAR 猛に滦するドライバの嘎肠に炳じて、VARBINARY または LONGVARBINARY 猛にマッピングされます。ほとんどの眷圭、CHAR と VARCHAR の联买は脚妥ではありません。ドライバによって努磊に联买されます。BINARY と VARBINARY の联买も票屯です。
この山は、ResultSet.getObject および CallableStatement.getObject メソッドで蝗われる、JDBC の房から Java のオブジェクト房へのマッピングを绩しています。
この山は、タ〖ゲットの JDBC の房を绩すパラメ〖タが回年されない眷圭に、PreparedStatement.setObject メソッドで蝗われるマッピングです。PreparedStatement.setObject メソッドに滦して回年できる JDBC の房は、山 8.5 を徊救してください。
String に滦するマッピングは奶撅 VARCHAR ですが、猛が VARCHAR 猛に滦するドライバの嘎肠を亩えている眷圭は、LONGVARCHAR になることに庙罢してください。byte[] の眷圭も票屯で、VARCHAR 猛に滦するドライバの嘎肠に炳じて、VARBINARY または LONGVARBINARY になります。
≈x∽は、その Java のオブジェクト房を滦炳する JDBC の房に恃垂できる眷圭があることを绩しています。この山は、 PreparedStatement.setObject または RowSet.setObject メソッドに畔すタ〖ゲット娄の JDBC の房を回年するパラメ〖タの材墙拉を绩しています。回年した猛が痰跟な眷圭、いくつかの恃垂は悸乖箕に己窃します。
 [D]
[D]
SQLInput.readXXX メソッドがサポ〖トしているのは、夸京されている恃垂だけです。≈x∽は、そのメソッドが JDBC の房を≈艰り叫せること∽を罢蹋します。X∽は、そのメソッドが JDBC の房を艰り叫のに≈夸京されていること∽を罢蹋します。
デ〖タベ〖スごとに、サポ〖トされている SQL の房は络きく佰なっています。山 8.7 は、肩妥なデ〖タベ〖スについて、JDBC の房にもっとも夺いデ〖タベ〖ス盖铜の SQL の房を绩しています。デ〖タベ〖ス盖铜の房の叹涟の赂哼は、≈デ〖タベ〖ス盖铜の房が纳裁のセマンティクスを捏丁している眷圭があるにもかかわらず、滦炳している JDBC の房のセマンティクスを茫喇するのに、その涂えられた房が蝗脱されます。∽を绩しています。
庙罢¨
DATE または TIME、あるいはその尉数を崔めることができる DATE 房または DATETIME 房が捏丁されます。
VARCHAR と VARCHAR2 は、Oracle8 ではシノニムです。
LONGVARCHAR に滦して DB2 は、2G バイトの扩嘎とともに≈CLOB(n)∽もサポ〖トしています。
LONGVARBINARY に滦して、DB2 は、2G バイトの扩嘎とともに≈BLOB(n)∽もサポ〖トしています。
BINARY、VARBINARY、および LONGVARBINARY リテラルの胺いは、デ〖タベ〖スによって络きく佰なります。败竣材墙な数恕で猛を肋年するのに、PreparedStatement.setBytes を蝗うことをお传めします。
DATE、TIME、および TIMESTAMP リテラルの胺いは、デ〖タベ〖スによって络きく佰なります。败竣材墙な数恕で Date、Time、および Timestamp の猛を肋年を肋年するのに、JDBC SQL エスケ〖プ菇矢を蝗うことをお传めします。(≈Statement 柒の SQL エスケ〖プ菇矢∽を徊救)