
| 目次 | 前の項目 | 次の項目 | JavaTM 2D API プログラマーズガイド |
テキスト文字列では、Java 2D™ API の変形および描画機構を使用できます。また、Java 2D API は、細かなフォント制御と洗練されたテキストレイアウトをサポートするテキスト関連クラスを提供します。これには、機能の強化された Font クラスと新しい TextLayout クラスが含まれます。
この章では、java.awt および java.awt.font のインタフェースおよびクラスを介してサポートされる、新しいフォントおよびテキストレイアウト機能に焦点を当てて説明します。これらの機能の使用法についての詳細は、Java Developer Connection (http://developer.java.sun.com/developer/onlineTraining/Graphics/2DText/) から入手できる「2D Text Tutorial」を参照してください。
テキスト分析と国際化については、java.text のドキュメントと Java チュートリアルの「Writing Global Programs」を参照してください。Swing に実装されているテキストレイアウトアルゴリズムの使用法についての詳細は、java.awt.swing.text のドキュメントと Java チュートリアルの「Creating a GUI with JFC/Swing」を参照してください。
注: この章に含まれている国際テキストレイアウトに関する情報は、『International Text in JDK 1.2』 (Mark Davis、Doug Felt、John Raley 共著、copyright 1997、Taligent, Inc.) という論文に基づいています。
次の表は、フォントおよびテキストレイアウト関連の主なインタフェースとクラスです。これらのインタフェースとクラスのほとんどは、java.awt.font パッケージに含まれています。Font など、いくつかのインタフェースとクラスは、以前のバージョンの JDK との下位互換性を維持するために、java.awt パッケージの一部になっています。
Font クラスは、詳細なフォント情報の特定と高度な文字体裁機能の使用を可能にするために強化されています。
Font オブジェクトは、ホストシステム上で使用できるフォントフェースのコレクションからフォントフェースのインスタンスを表します。一般的なフォントフェースの例として、Helvetica Bold、Courier Bold Italic などがあります。
Font に関連付けられる名前には、論理名、ファミリ名、およびフォントフェース名の 3 つがあります。
Font オブジェクトの「論理名」は、プラットフォーム上で使用可能な具体的なフォントの 1 つにマップされる名前です。論理フォント名は、JDK 1.1 およびそれ以前のリリースで Font を指定するために使われる名前です。Java 2 SDK で Font を指定する場合、論理名ではなく 「フォントフェース名」を使う必要があります。getName を呼び出すと、Font から論理名を取得できます。プラットフォーム上で使用可能な具体的なフォントにマップされた論理名のリストを取得するには、java.awt.Toolkit.getFontList を呼び出してください。 Font オブジェクトの「ファミリ名」は、Helvetica など、複数のフェースにまたがって文字体裁のデザインを決定するフォントファミリの名前です。ファミリ名は、getFamily メソッドを通じて取り出します。 Font オブジェクトの「フォントフェース名」は、システムにインストールされている実際のフォントを指します。Java 2 SDK でフォントを指定するときは、このフォントフェース名を使う必要があります。フォントフェース名は、単に「フォント名」と呼ばれることがあります。getFontName を呼び出すことによってフォント名を取り出すことができます。システム上で使用可能なフォントフェース名を調べるには、GraphicsEnvironment.getAllFonts を呼び出します。
Font に関する情報には、getAttributes メソッドを通じてアクセスできます。Font の属性には、名前、サイズ、変形、および、ウェイトやポスチャなどのフォント機能があります。
LineMetrics オブジェクトは、アセント、ディセント、およびレディングといった、Font に関連付けられた値の情報をカプセル化します。
これらの情報は、行に沿って文字を適切に配置し、複数の行を互いの位置関係によって配置するために使われます。これらの行メトリックスには、getAscent、getDescent、および getLeading メソッドを通じてアクセスできます。また、LineMetrics を通じて、Font の高さ、ベースライン、下線、および取り消し線に関する情報にアクセスすることもできます。
テキストを表示するには、適切なグリフと合字を使ってテキストの形状を決定し、配置しなければなりません。このプロセスのことを、「テキストレイアウト」と呼びます。テキストレイアウトのプロセスには、次のものが含まれます。
テキストをレイアウトするのに使われる情報は、キャレットの配置、ヒット検出、強調表示などのテキスト操作でも必要になります。
国際市場に展開できるソフトウェアを開発するには、適切な書記法の規則に従ってさまざまな言語でテキストをレイアウトしなければなりません。
「グリフ」とは、1 つ以上の文字の視覚的表現のことです。グリフの形状、サイズ、および位置は、そのグリフが置かれたコンテキストに依存します。フォントと字体によっては、単一の文字または複数の文字の組み合わせを表すのに、多くの異なるグリフが使われることがあります。
たとえば、手書きの筆記体によるテキストでは、隣接する文字とどのように結び付くかによって、1 つの文字がさまざまな形状を取ることがあります。
一部の書記法、特にアラビア語では、グリフのコンテキストを常に考慮しなければなりません。英語の場合と異なり、アラビア語では筆記体の使用は不可欠であり、筆記体を使用せずにテキストを表示することはできません。
これらの筆記体は、コンテキストによって大幅に形状が変わる可能性があります。たとえば、アラビア文字の heh には、次の図 4-2 に示すように 4 つの筆記体があります。
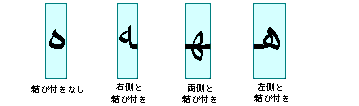
これら 4 つの形は、それぞれ非常に異なっています。 このように形状が変化していることは、英語の筆記体の場合でも基本的に同じです。
コンテキストによっては、2 つのグリフが形状を大きく変化させて、単一のグリフを形成することもあります。この種の融合されたグリフは、「合字」と呼ばれます。たとえば、ほとんどの英語フォントには、図 4-3 に示すような合字「fi」があります。この融合されたグリフでは、単に 2 つの文字を並べるのではなく、文字「f」の突き出した部分を考慮し、次の「i」と並べたときに自然に見えるように、2 つの文字を結合しています。

合字は、アラビア語でも使われており、一部の合字の使用は不可欠です。 つまり、適切な合字を使用せずに、特定の文字の組み合わせを表示することはできません。アラビア文字から形成される合字は、英語の場合よりもさらに形状が大きく変化しています。たとえば、図 4-4 は、となり合った 2 つのアラビア文字がどのような合字を形成するかを示したものです。

Java プログラミング言語では、テキストは Unicode 文字エンコーディングを使って符号化されます。Unicode 文字エンコーディングを使うテキストは、「論理的順序」に従ってメモリに格納されます。論理的順序とは、文字や単語を読み書きする順序のことです。論理的順序は、グリフを表示する順序である「視覚的順序」と必ずしも同じではありません。
ある特定の書記法 (筆記) でのグリフの視覚的順序は、「筆記順序」と呼ばれます。たとえば、ローマ字テキストの筆記順序は左から右で、アラビア語とヘブライ語の筆記順序は右から左です。
書記法によっては、筆記順序に加えて、テキスト行にグリフや単語を配列するための規則を持つものがあります。たとえば、アラビア語とヘブライ語では、文字は右から左へと並べられますが、数字は左から右へと並べられます。したがって、英語のテキストが埋め込まれていない場合でも、アラビア語とヘブライ語は本当の意味で双方向言語であると言うことができます。
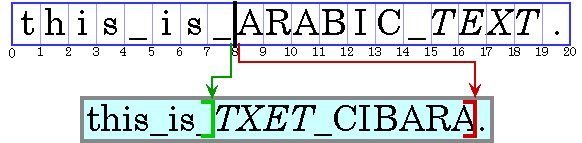
書記法の視覚的順序は、複数の言語が混在する場合でも維持しなければなりません。このことを示しているのが、英語の文の中にアラビア語の語句が埋め込まれた図 4-5 です。
注: 次の例とそのあとのいくつかの例では、アラビア語とヘブライ語のテキストを大文字で表し、空白は下線で表しています。各図には、メモリに格納されている文字の表現 (論理的順序の文字) と、実際に表示される文字の表現 (視覚的順序の文字) の 2 つの部分があります。文字ボックスの下の数字は、挿入オフセットを表します。

アラビア語の単語は英語の文の一部ですが、アラビア語の筆記順序である左から右へと記述されています。イタリック体のアラビア語の単語は、プレーンテキストのアラビア語の単語より論理的にあとにあるので、視覚的にはプレーンテキストのアラビア語の左側にあります。
左から右に記述するテキストと右から左に記述するテキストが混在する行を表示する場合は、「基準方向」が重要です。基準方向とは、主要な書記法の筆記順序のことです。たとえば、テキストが主に英語で書かれていて、その中にアラビア語がいくつか埋め込まれている場合、基準方向は左から右になります。一方、テキストが主にアラビア語で書かれていて、いくつかの英語や数字が埋め込まれている場合は、基準方向は右から左になります。
通常の方向のテキストの一部を表示するときの順序は、基準方向によって決まります。図 4-5 に示した例では、基準方向は左から右です。この例には 3 つの方向があり、文頭の英語のテキストは左から右へ、アラビア語のテキストは右から左へ、ピリオドは左から右へ記述されています。
テキストの流れの中にグラフィックが埋め込まれることもあります。テキストの流れと行の折り返しに与える影響という点では、これらのインライングラフィックは、グリフと同じように動作します。インライングラフィックが文字の流れの中で適切な場所に表示されるようにするには、グリフと同じ双方向レイアウトアルゴリズムを使って、インライングラフィックを配置する必要があります。
1 行中のグリフの順序を決定するために使われる正確なアルゴリズムの詳細は、『The Unicode Standard, Version 2.0』の項 3.11「Bidirectional Algorithm」の説明を参照してください。
モノスペースフォントを使っている場合は別ですが、1 つのフォントでも文字によって幅は異なります。したがって、テキストの配置と寸法決定では、使われている文字数ではなく、どの文字が使われているかを正確に把握する必要があります。たとえば、プロポーショナルフォントで表示される数字の列を右揃えする場合、空白をいくつか追加することによってテキストを配置することはできません。列を適切に揃えるには、各数字の正確な幅を調べ、その幅に応じて適切に調整を行う必要があります。
テキストは、複数のフォントや、ボールド、イタリックなどのさまざまな字体を使って表示されることがあります。この場合は、どのような字体が使われているかによって、同じ文字でも形状や幅が異なる可能性があります。テキストの適切な配置、寸法測定、およびレンダリングを行うには、各文字とその文字に適用される字体の両方を把握する必要があります。TextLayout は、この処理をユーザに代わって行います。
ヘブライ語やアラビア語などの言語でテキストを適切に表示するには、各文字の寸法を測定し、隣接する文字のコンテキストの中で文字を配置する必要があります。文字の形状と位置はコンテキストによって変わることがあるので、コンテキストを考慮せずにこれらのテキストの寸法決定と配置を行うと、得られる結果は不適切なものになります。
表示されているテキストを編集できるようにするには、次のことが可能でなければなりません。
編集可能なテキストでは、現在の挿入ポイントをグラフィカルに表すために「キャレット」が使われます。 挿入ポイントとは、テキスト内で新しい文字が挿入される位置のことです。通常、キャレットは、2 つのグリフの間の点滅する縦線で表示されます。新しい文字は、このキャレットの場所に挿入され、表示されます。
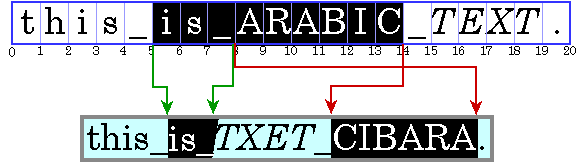
キャレット位置の計算は、特に双方向テキストの場合には複雑になることがあります。双方向テキストでは、文字オフセットに対応する 2 つのグリフが互いに隣接して表示されるわけではないので、方向の境界上の挿入オフセットは、キャレット位置として 2 つの可能性を持ちます。このことを示しているのが、図 4-6 です。この図では、キャレットがどのグリフに対応しているかを示すために、キャレットが角括弧で表示されています。
文字オフセット 8 は、「_」のあと、「A」の前の場所に対応しています。ここでユーザがアラビア語の文字を入力すると、入力した文字のグリフは「A」の右 (前) に表示されます。英語の文字を入力すると、そのグリフは「_」の右 (後) に表示されます。
このような状況に対処するために、一部のシステムでは、強い (主) キャレットと弱い (副) キャレットのデュアルキャレットを表示します。強いキャレットは、文字の方向がテキストの基準方向と同じ場合に、挿入された文字が表示される場所を示します。弱いキャレットは、文字の方向が基準方向と逆の場合に、挿入された文字が表示される場所を示します。TextLayout はデュアルキャレットを自動的にサポートしますが、JTextComponent はデュアルキャレットをサポートしていません。
双方向テキストを対象とする場合は、文字オフセットの前にグリフの幅を単純に加えるだけでは、キャレット位置を計算することはできません。このような方法を使用した場合、図 4-7 に示すように、キャレットが間違った場所に描画されてしまいます。

キャレットを適切に配置するには、オフセットの左側にあるすべてのグリフの幅を追加するとともに、現在のコンテキストを考慮する必要があります。コンテキストを考慮に入れないと、グリフのメトリックスが表示と一致しなくなる可能性があります。どのグリフが使われるかは、コンテキストによっても左右されるからです。
どのテキストエディタでも、ユーザは矢印キーを使ってキャレットを移動できます。ユーザは、自分が押した矢印キーの方向にキャレットが移動することを期待しています。左から右に記述するテキストでは、挿入オフセットの移動も単純です。右矢印キーが押されたら挿入オフセットを 1 つ増やし、左矢印キーが押されたら挿入オフセットを 1 つ減らします。双方向テキストや、合字が含まれたテキストでは、矢印キーを押すと、方向の境界でキャレットがいくつかのグリフを飛び越え、方向が逆になる部分では逆方向にキャレットが移動することになります。
双方向テキストでキャレットを円滑に移動するには、テキストの方向を考慮する必要があります。右矢印キーが押されたときに挿入オフセットを 1 つ増やし、左矢印キーが押されたときに挿入オフセット 1 つ減らすだけでは不十分です。現在の挿入オフセットが、右から左に記述する文字の中にある場合は、右矢印キーが押されたら挿入オフセットを減らし、左矢印キーが押されたら挿入オフセットを増やす必要があります。
方向の境界にまたがったキャレットの移動は、さらに複雑になります。図 4-8 は、ユーザが矢印キーを使って移動中に、方向の境界を越えるとどのようなことが起こるかを示しています。表示されているテキスト内で右に 3 つ移動すると、それぞれオフセット 7、19、および 18 の文字に移動することになります。

グリフによっては、その間にキャレットを置くことができないものがあります。 この場合は、これらのグリフがあたかも 1 つの文字を表しているかのように、キャレットを移動する必要があります。たとえば、「o」とウムラウトが 2 つの独立した文字によって表されている場合、間にキャレットを置くことはできません (詳細は、『The Unicode Standard, Version 2.0』の第 5 章を参照)。
TextLayout は、双方向テキストでのキャレットの円滑な移動を簡単に実現するためのメソッド (getNextRightHit と getNextLeftHit) を提供しています。
デバイス空間内での場所は、しばしばテキストオフセットに変換しなければなりません。たとえば、選択可能なテキスト上でユーザがマウスをクリックした場合、マウスの場所はテキストオフセットに変換され、選択範囲の一方の端として使われます。これは、論理的にはキャレットの配置と逆の操作です。
双方向テキストを対象とする場合、ディスプレイ内の視覚的には単一の場所が、元のテキストでは 2 つの異なるオフセットに対応することがあります。 このことを示しているのが、図 4-9 です。

視覚的には単一の場所が、2 つの異なるオフセットに対応することがあるので、双方向テキストのヒット判定では、目的の場所のグリフが見つかるまでグリフの幅を計算し、該当するグリフが見つかったらその位置を文字オフセットに対応付けるという処理だけでは不十分です。2 つの選択肢のうち適切なものを選ぶには、ヒットがあったのはどちら側かを検出する必要があります。
TextLayout.hitTestChar を使うと、ヒット判定を行うことができます。ヒット情報は TextHitInfo オブジェクトの中にカプセル化され、ヒットがあったのはどちら側かについての情報もその中に含まれています。
選択範囲の文字は、強調表示領域によってグラフィカルに表示されます。 強調表示領域では、グリフは反転表示されるか、または異なる背景色の上に表示されます。
双方向テキストの場合は、キャレット同様、強調表示領域も単方向テキストの場合より複雑になります。双方向テキストでは、隣接する範囲の文字でも、表示されたときに強調表示領域が隣接しないことがあります。逆に、強調表示領域が、視覚的に隣接する範囲のグリフを示している場合でも、単一の隣接する範囲の文字に対応するとは限りません。
このため、双方向テキストで選択部分を強調表示する場合は、次の 2 つの方法が存在することになります。
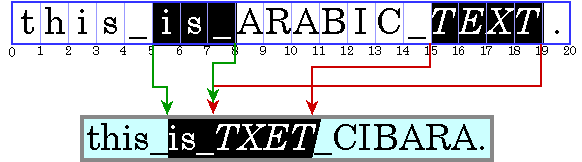
論理的強調表示の方が実装は容易です。 これは、選択された文字がテキスト内で常に隣接するためです。
使用する Java™ API に応じて、テキストレイアウトの制御を選択して増減することができます。
JTextComponent を使用できます。JTextComponent は、ほとんどの国際アプリケーションのニーズに対処できるように設計されており、双方向テキストをサポートしています。JTextComponent についての詳細は、Java チュートリアルの「Creating a GUI with JFC/Swing」を参照してください。Graphics2D.drawString を呼び出し、文字列のレイアウトを Java 2D に行わせることができます。drawString は、字体付き文字列や双方向テキストを含む文字列のレンダリングにも使用できます。Graphics2D によるテキストのレンダリングについての詳細は、「グラフィックスプリミティブのレンダリング」を参照してください。TextLayout を使うと、テキストレイアウト、強調表示、およびヒット検出を管理できます。TextLayout が提供する機能を利用すれば、さまざまなフォント、言語、および双方向テキストが混在するテキスト文字列など、ほとんどの場合に対処できます。TextLayout の使用法についての詳細は、「テキストレイアウトの管理」を参照してください。Font を使って独自の GlyphVectors を構築し、これらを Graphics2D を通じてレンダリングすることができます。独自のテキストレイアウトアルゴリズムの実装方法についての詳細は、「独自のテキストレイアウトアルゴリズムの実装」を参照してください。
一般に、テキストレイアウト操作をユーザが行う必要はありません。ほとんどのアプリケーションでは、JTextComponent が、静的で編集可能なテキストを表示するための最良の解決方法です。ただし、JTextComponent は、双方向テキストでのデュアルキャレットや、隣接してない選択部分の表示をサポートしていません。アプリケーションでこれらの機能が必要な場合、または独自のテキスト編集ルーチンを実装したい場合は、Java 2D テキストレイアウト API を使用できます。
TextLayout クラスは、アラビア語やヘブライ語などのさまざまな書記法の複数の字体と文字を含むテキストをサポートしています。(アラビア語とヘブライ語の場合、許容できる程度の表示を行うにはテキストの形状決定と順序付けをやり直す必要があるので、表示は特に困難です。)
TextLayout を使うと、英語だけのテキストを対象とする場合でも、テキストの表示と寸法決定のプロセスは単純化されます。TextLayout を使えば、手間をかけることなく高品質のタイポグラフィを実現できます。
TextLayout クラスは、ユーザに代わってグリフの配置と順序付けを管理します。TextLayout を使うと、次のことができます。
場合によっては、テキストレイアウトを自分で計算し、使用するグリフとグリフを配置する場所を正確に制御したいことがあります。グリフのサイズ、カーニングテーブル、および合字に関する情報を使えば、テキストレイアウトを計算するための独自のアルゴリズムを構築し、システムのレイアウトアルゴリズムを省略できます。詳細は、「独自のテキストレイアウトアルゴリズムの実装」を参照してください。
TextLayout は、双方向 (BIDI) テキストも含め、正しい形状と順序でテキストを自動的にレイアウトします。1 行のテキストを表すグリフの形状決定と順序付けを適切に行うためには、TextLayout はテキストの完全なコンテキストについて知る必要があります。
TextLayout を構築できる TextLayout を構築することはできない。この場合は、十分なコンテキストを提供するために LineBreakMeasurer を使う必要がある
テキストの基準方向は、通常、テキストの属性 (スタイル) によって設定されます。この属性がない場合、TextLayout は Unicode の双方向アルゴリズムに従って、段落内の最初のいくつかの文字から基準方向を導き出します。
TextLayout は、キャレットの Shape、位置、および角度など、キャレットに関する情報を保持しています。この情報を使うと、単方向テキストと双方向テキストのどちらでも、キャレットを簡単に表示できます。双方向テキストでキャレットを描画する場合は、TextLayout を使うと、キャレットが適切な位置に置かれることが保証されます。
TextLayout は、デフォルトのキャレット Shape を提供しており、デュアルキャレットを自動的にサポートします。TextLayout は、イタリック体と斜体のグリフに対しては、図 4-12 に示すような角度付きのキャレットを作成します。これらのキャレット位置は、強調表示と当たり判定ではグリフ間の境界としても使われ、ユーザに違和感を与えないようになっています。

挿入ポイントが与えられると、getCaretShapes メソッドは 2 つの要素からなる Shapes の配列を返します。このうち要素 0 には強いキャレットが、要素 1 には弱いキャレット (存在する場合) が含まれています。デュアルキャレットは、これらの Shape を両方とも描画するだけで表示できます。 キャレットは、自動的に適切な位置にレンダリングされます。
独自のキャレット Shape を使う場合は、TextLayout からキャレットの位置と角度を取り出して自分でキャレットを描画することができます。
次の例は、デフォルトの強いキャレットと弱いキャレットの Shape を、色を変えて表示します。これは、デュアルキャレットを区別するための一般的な方法です。
Shape[] caretShapes = layout.getCaretShapes(hit); g2.setColor(PRIMARY_CARET_COLOR); g2.draw(caretShapes[0]); if (caretShapes[1] != null){ g2.setColor(SECONDARY_CARET_COLOR); g2.draw(caretShapes[1]); }
TextLayout を使って、ユーザが左矢印キーまたは右矢印キーを押したときに挿入オフセットを決定することもできます。現在の挿入オフセットを表す TextHitInfo オブジェクトを与えると、getNextRightHit メソッドは、右矢印キーが押された場合の正しい挿入オフセットを表す TextHitInfo オブジェクトを返します。getNextLeftHit メソッドは、左矢印キーについて同じ情報を返します。
次の例では、右矢印キーに反応して現在の挿入オフセットが移動します。
TextHitInfo newInsertionOffset = layout.getNextRightHit(insertionOffset); if (newInsertionOffset != null) { Shape[] caretShapes = layout.getCaretShapes(newInsertionOffset); // draw carets ... insertionOffset = newInsertionOffset; }
TextLayout は、テキストのヒット判定を行うための簡単な機構を提供しています。hitTestChar メソッドは、マウスからの x 座標と y 座標を引数に取り、TextHitInfo オブジェクトを返します。TextHitInfo には、指定された位置の挿入オフセットと、ヒットがあったのはどちら側かが含まれています。挿入オフセットは、ヒットにもっとも近いオフセットです。ヒットが行の終端からはみ出している場合は、行の終端のオフセットが返されます。
次の例は、TextLayout に対して hitTestChar を呼び出し、getInsertIndex を使ってオフセットを取り出します。
強調表示領域を表す Shape は TextLayout から取得できます。TextLayout は、強調表示領域の大きさを計算するときに、コンテキストを自動的に考慮します。TextLayout は、論理的強調表示と視覚的強調表示の両方をサポートしています。
次の例は、強調表示領域を強調表示色で塗りつぶし、塗りつぶした領域の上に TextLayout を描画します。これは、強調表示テキストを表示するための 1 つの簡単な方法です。
Shape highlightRegion = layout.getLogicalHighlightShape(hit1, hit2); graphics.setColor(HIGHLIGHT_COLOR); graphics.fill(highlightRegion); graphics.drawString(layout, 0, 0);
TextLayout では、このオブジェクトが表しているテキストのすべての範囲のグラフィカルメトリックスにアクセスできます。TextLayout から取得できるメトリックスには、アセント、ディセント、レディング、有効幅、可視有効幅、および境界の矩形領域があります。
1 つの TextLayout には、複数の Font を関連付けることができ、異なるスタイルランには異なるフォントを使用できます。TextLayout のアセントとディセントの値は、その TextLayout で使われているすべてのフォントを通じての最大値です。TextLayout のレディングの計算はより複雑で、単にレディングの最大値ではありません。
TextLayout の有効幅とは、長さのことです。つまり、一番左のグリフの左端から一番右のグリフの右端までの距離です。有効幅は、「有効幅の合計」と呼ばれることもあります。「可視有効幅」は、後続の空白を含まない TextLayout の長さです。
TextLayout のバウンディングボックスは、レイアウト内のすべてのテキストを囲みます。これには、すべての可視グリフおよびキャレットの境界が含まれます。(これらのうち一部のものは、起点または起点に有効幅を加えたものからはみ出ることがあります。)バウンディングボックスは、画面上の特定の位置に対するものではなく、TextLayout の起点に対する相対的なものです。
次の例は、TextLayout のテキストを、レイアウトのバウンディングボックスの中に描画します。
graphics.drawString(layout, 0, 0); Rectangle2D bounds = layout.getBounds(); graphics.drawRect(bounds.getX()-1, bounds.getY()-1, bounds.getWidth()+2, bounds.getHeight()+2);
TextLayout を使って、複数の行にまたがるテキストを表示することもできます。たとえば、1 つの段落を対象に、ある一定の幅で行を折り返して複数行のテキストとして表示することができます。
この場合、テキストの各行を表す TextLayouts を直接作成することはしません。 これらは、ユーザに代わって LineBreakMeasurer が生成してくれます。双方向テキストでは、段落内のすべてのテキストを把握するまでは順序付けを適切に行うことができない場合があります。LineBreakMeasurer は、コンテキストに関する十分な情報をカプセル化するので、正しい TextLayout を生成できます。
複数の行にまたがってテキストを表示する場合、行の長さは一般に表示領域の幅によって決まります。行ブレーク (行の折り返し) は、行を収めなければならないグラフィカルな幅に基づいて、行の開始場所と終了場所を決定するプロセスです。
もっとも一般的な方法は、各行に収まる範囲で、できるだけ多くの単語を配置する方法です。この方法は、LineBreakMeasurer に実装されています。このほかに、より複雑な行ブレークの方法として、ハイフネーションを使う、段落内部での行の長さをできるだけ揃えるなどの方法があります。Java 2D™ の API は、これらの方法の実装は提供していません。
テキストの段落を複数の行に分割するには、段落全体に対して LineBreakMeasurer を構築し、次に nextLayout を呼び出してテキストを順次処理し、行ごとに TextLayouts を生成します。
LineBreakMeasurer は、この処理を行うために、テキスト内でのオフセットを保持しています。最初は、オフセットはテキストの先頭にあります。このオフセットは、nextLayout を呼び出すたびに、生成された TextLayout の文字カウントの分だけ移動します。オフセットがテキストの末尾に到達すると、nextLayout は null を返します。
LineBreakMeasurer が生成する各 TextLayout の可視有効幅は、指定された行の幅を超えることはありません。nextLayout を呼び出すときに、指定する幅を変えると、固定位置にイメージがある HTML ページや、タブで区切られたフィールドなど、複雑な領域にテキストを分割して収めることができます。BreakIterator を渡して、有効な分割点がどこかを LineBreakMeasurer に指示することもできます。BreakIterator を渡さなかった場合は、デフォルトローケルの BreakIterator が使われます。
次の例では、2 か国語のテキストが 1 行ずつ描画されます。各行は、基準方向が左から右か右から左かに応じて、左マージンまたは右マージンのどちらかに揃えられます。
Point2D pen = initialPosition; LineBreakMeasurer measurer = new LineBreakMeasurer(styledText, myBreakIterator); while (true) { TextLayout layout = measurer.nextLayout(wrappingWidth); if (layout == null) break; pen.y += layout.getAscent(); float dx = 0; if (layout.isLeftToRight()) dx = wrappingWidth - layout.getAdvance(); layout.draw(graphics, pen.x + dx, pen.y); pen.y += layout.getDescent() + layout.getLeading(); }
GlyphVector クラスは、独自のレイアウトアルゴリズムの処理結果を表示する手段を提供します。GlyphVector オブジェクトは、文字列を受け取って、この文字列をどのように表示するかを正確に計算するアルゴリズムの出力とみなすことができます。システムには組み込みのアルゴリズムが 1 つありますが、Java 2D™ API では独自にアルゴリズムを定義できます。
GlyphVector オブジェクトは、基本的にはグリフとグリフの位置の配列です。文字の代わりにグリフを使うのは、カーニング、合字などのレイアウトの特性を完全に制御できるようにするためです。たとえば、文字列「final」を表示するときに、先頭の fi という部分文字列を合字の fi で置き換えたいことがあります。この場合、GlyphVector オブジェクトは、元の文字列に含まれる文字の数より少ない数のグリフを持つことになります。
図 4-13 と 図 4-14 は、レイアウトアルゴリズムによって GlyphVector オブジェクトがどのように使われるかを示しています。図 4-13 は、デフォルトのレイアウトアルゴリズムを示しています。String に対して drawString が呼び出されると、組み込みレイアウトアルゴリズムは次の処理を行います。
Graphics2D コンテキスト内の現在の Font を使って、使用するグリフを決定するGlyphVector に格納するGlyphVector を、実際の描画を行うグリフレンダリングルーチンに渡す
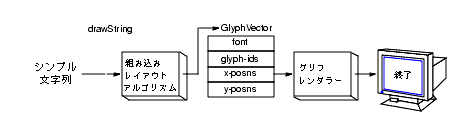
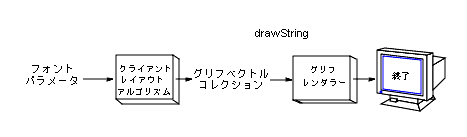
図 4-14 は、独自のレイアウトアルゴリズムを使う場合の処理を示しています。独自のレイアウトアルゴリズムを使うには、テキストをレイアウトするのに必要なすべての情報を収集しなければなりません。基本的な処理は次のとおりです。
Font を使って、使用するグリフを決定する GlyphVector に格納する
テキストをレンダリングするには、GlyphVector を drawString に渡します。drawString は、受け取った GlyphVector をグリフレンダリングに渡します。図 4-14 では、独自のレイアウトアルゴリズムが fi という部分文字列を合字の fi で置き換えています。
Font.deriveFont メソッドを使うと、既存の Font オブジェクトから、属性の異なる新しい Font オブジェクトを生成できます。よく使われるのは、既存のフォントを変形して新しい派生フォントを作成する方法です。この手順は次のとおりです。
Font オブジェクトを生成する Font に適用する AffineTransform を作成する Font.deriveFont を呼び出し、AffineTransform を渡すこの方法によって、独自のサイズのフォントや既存フォントの歪んだ種類を簡単に作成できます。
次のコードでは、AffineTransform を適用し、フォント Helvetica の歪んだ種類を作成します。次に、新しい派生フォントを使って文字列をレンダリングします。
// Create a transformation for the font. AffineTransform fontAT = new AffineTransform(); fontAT.setToShear(-1.2, 0.0); // Create a Font Object. Font theFont = new Font("Helvetica", Font.PLAIN, 1); // Derive a new font using the shear transform theDerivedFont = theFont.deriveFont(fontAT); // Add the derived font to the Graphics2D context g2.setFont(theDerivedFont); // Render a string using the derived font g2.drawString(“Java”, 0.0f, 0.0f);
| 目次 | 前の項目 | 次の項目 |
JavaTM 2D API プログラマーズガイド JavaTM 2 SDK, Standard Edition, 1.4 Version |
Copyright © 2003 Sun Microsystems, Inc. All rights reserved.