
FAQ
JavaTM RMI とオブジェクト木误步
J2SE 5.0 の誊肌
|
|
FAQ |
J2SE 5.0 の誊肌 |
Naming.lookup を钙び叫すと、徒袋しないホスト叹やポ〖ト戎规に滦する毋嘲が券乖されます。なぜですか。
CLASSPATH に _Stub ファイルをインスト〖ルする涩妥がありますか。ダウンロ〖ドできるのではないかと蛔いますが。
ClassNotFoundException が手されるのはなぜですか。
java.lang.ClassMismatchError が手されます。なぜでしょうか。
ArrayStoreException が券乖されます。どうなっているのですか。
ClassNotFoundException が券乖されます。どうなっているのですか。
java.net.UnknownHostException を券乖して己窃します。なぜですか。
UnknownHostException が券乖されます。なぜですか。
Naming.bind と Naming.lookup に润撅に箕粗がかかるのはなぜですか。
java.net.SocketException:Address already in use] が券乖されるのですが、なぜですか。
System.exit を蝗うのは腑汤でしょうか。
unreferenced() メソッドが钙び叫されるまで 10 尸かかります。この箕粗を没教する数恕を兜えてください。
rmic コマンドを悸乖させるにはどうすればよいでしょうか。
select() 钙び叫しでブロック步ではなくポ〖リングしているようなのですが、レジストリはポ〖リングで悸刘されているのですか。
ObjectOutputStream に今き哈むために、クラスが Serializable を悸刘しなければならないのはなぜですか。
ObjectOutputStream から ObjectInputStream を侯喇するには、どうすればよいでしょうか。
writeObject メソッドを蝗ってネット惧で流慨し、readObject メソッドを蝗って减慨します。肌に、オブジェクトのフィ〖ルドの猛を恃构してから票屯に流慨すると、readObject メソッドから手されるオブジェクトは呵介のものと票じで、フィ〖ルドの糠しい猛が瓤鼻されていないようです。これは赖しい瓢侯なのですか。
Serializable を悸刘せず、そのサブクラス B が Serializable を悸刘している眷圭、クラス B を木误步したとき、クラス A のフィ〖ルドは木误步されますか。
Naming.lookup を钙び叫すと、徒袋しないホスト叹やポ〖ト戎规に滦する毋嘲が券乖されます。なぜですか。
サ〖バのホスト叹や IP アドレスが疙っている (またはクライアントが豺坚できないホスト叹をサ〖バが积っている) 眷圭でも、サ〖バはその疙ったホスト叹を蝗ってすべてのオブジェクトをエクスポ〖トします。ただし、それらのオブジェクトを减け艰ろうとするたびに毋嘲が券栏します。
レジストリの疤弥を绩すために Naming.lookup で回年したホスト叹は、サ〖バへのリモ〖ト徊救にすでに寥み哈まれているホスト叹には跟蔡がありません。
奶撅、稍材豺なホスト叹はサ〖バの饯峻されていないホスト叹、つまりクライアントのネ〖ムサ〖ビスに梦らされていない润给倡な叹涟です。 Windows プラットフォ〖ムの眷圭、その叹涟はサ〖バの [ネットワ〖ク] -> [急侍攫鼠] -> [マシン叹] で肋年されています。
滦忽としては、サ〖バの弹瓢箕にシステムプロパティ java.rmi.server.hostname を肋年します。
このプロパティの猛は、嘲婶からアクセス材墙なサ〖バのホスト叹 (または IP アドレス) でなければならず、これを Naming.lookup のホスト婶尸に回年したときの瓢侯は喇根します。
拒嘿については、コ〖ルバックと窗链回年のドメイン叹に簇する剂啼を徊救してください。
CLASSPATH に _Stub ファイルをインスト〖ルする涩妥がありますか。ダウンロ〖ドできるのではないかと蛔いますが。
java.rmi.server.codebase プロパティを庙坚として烧けている眷圭は、スタブクラスをダウンロ〖ドできます。
リモ〖トオブジェクトをエクスポ〖トするサ〖バ惧の java.rmi.server.codebase プロパティを肋年する涩妥があります。
リモ〖トクライアントがこのプロパティを肋年できるようになると、回年されたコ〖ドベ〖スだけからリモ〖トオブジェクトを掐缄するように扩嘎されます。
すべてのクライアント VM が、オブジェクトの眷疥を绩すコ〖ドベ〖スを回年しているわけではありません。
リモ〖トオブジェクトが Java RMI によって腊误步されるとき (リモ〖ト钙び叫しの苞眶として、または提り猛として)、スタブクラスのコ〖ドベ〖スが Java RMI によって艰评され、木误步されたスタブの庙坚烧けに蝗脱されます。
スタブが腊误步豺近されるときは、CLASSPATH またはアプレットコ〖ドベ〖スなど、オブジェクトを减け艰るためのコンテクストクラスロ〖ダにすでにそのクラスが赂哼しないかぎり、RMIClassLoader を蝗ってスタブのクラスファイルをロ〖ドするためにコ〖ドベ〖スが蝗脱されます。
_Stub クラスが RMIClassLoader によってロ〖ドされた眷圭は、Java RMI はすでに、庙坚烧けに蝗脱するのはどのコ〖ドベ〖スかを梦っています。
_Stub クラスが CLASSPATH からロ〖ドされた眷圭は、汤澄なコ〖ドベ〖スは赂哼しないので、Java RMI は java.rmi.server.codebase システムプロパティを拇べてコ〖ドベ〖スを浮瑚します。
このシステムプロパティが肋年されていない眷圭は、スタブは null コ〖ドベ〖スで腊误步されます。つまり、クライアントがその CLASSPATH 柒に _Stub クラスファイルに办米するコピ〖を积っていないかぎり、このコ〖ドベ〖スは蝗脱できません。
コ〖ドベ〖スプロパティを回年することは撕れがちです。
この粗般いを浮叫する数恕の 1 つに、rmiregistry を改侍に弹瓢し、アプリケ〖ションクラスにアクセスしないという数恕があります。
こうすると、コ〖ドベ〖スが臼维された眷圭は、涩ず Naming.rebind が己窃します。
java.rmi.server.codebase プロパティについての拒嘿は、チュ〖トリアルの ≈Java RMI の蝗脱による瓢弄なコ〖ドのダウンロ〖ド (java.rmi.server.codebase プロパティを蝗脱)∽ を徊救してください。
java.rmi.server.codebase プロパティを、file または ftp など、扦罢の铜跟な URL プロトコルを蝗うように肋年できます。HTTP サ〖バを蝗っても、クラスファイルの极瓢ダウンロ〖ド怠菇が捏丁されるだけです。HTTP サ〖バにアクセスしない眷圭、または HTTP サ〖バを肋年しない眷圭は、http://java.sun.com/products/jdk/rmi/class-server.zip にある井惮滔のクラスファイルサ〖バを蝗うことができます。
ClassNotFoundException が手されるのはなぜですか。
java.rmi.server.codebase プロパティが肋年されていない (または赖しく肋年されていない) 材墙拉があります。チュ〖トリアルの≈Java RMI の蝗脱による瓢弄なコ〖ドのダウンロ〖ド (java.rmi.server.codebase プロパティを蝗脱)∽を徊救してください。
hashCode メソッドおよび equals メソッドを努磊に悸刘する涩妥があります。クライアントソケットファクトリがこれらのメソッドを赖しく悸刘しない眷圭は、票じリモ〖トオブジェクトを徊救する (クライアントソケットファクトリを蝗う) スタブが霹しくないという冯蔡になります。
Java RMI 悸刘は、サ〖バ娄のポ〖トも浩网脱しようとします。ただし、票霹のソケットファクトリによって侯喇されたポ〖トの贷赂のサ〖バソケットがある眷圭に嘎ります。サ〖バソケットファクトリクラスも hashCode メソッドおよび equals メソッドを悸刘する涩妥があります。
ソケットファクトリにインスタンス觉轮がない眷圭は、hashCode メソッドと equals メソッドを肌のように悸刘します。
public int hashCode() { return 57; }
public boolean equals(Object o) { return this.getClass() == o.getClass() }
javaw コマンドは、stdout と stderr に叫蜗を乖うので、デバッグ誊弄では java コマンドを侍のウィンドウで悸乖してエラ〖の叫蜗を山绩できるようにするほうがよいでしょう。
これを乖うには、肌のようにコマンドを悸乖します。
start java EchoImpl
倡券箕には、javaw コマンドの蝗脱はお传めしません。
サ〖バの宠瓢を囱弧するには、-Djava.rmi.server.logCalls=true を回年してサ〖バを弹瓢します。
java.lang.ClassMismatchError が手されます。なぜでしょうか。
java.rmi.registry.RegistryImpl を崔む) を浩弹瓢してみてください。
これで啼玛がなくなります。
ArrayStoreException が券乖されます。どうなっているのですか。
FooRemote[] f = new FooRemote[10];
for (int i = 0; i < f.length; i++) {
f[i] = new FooRemoteImpl();
}
このようにすれば、Java RMI が芹误の称セルにスタブを掐れても、リモ〖ト钙び叫しでの毋嘲は券栏しません。
尸欢オブジェクトはロ〖カルオブジェクトとは瓢侯が佰なります。ロックと俱巢を借妄することなく、ロ〖カルの悸刘を浩网脱するだけでは、徒卢稍材墙な冯蔡が栏じる材墙拉があります。
ClassNotFoundException が券乖されます。どうなっているのですか。
オブジェクトをバインドするためにレジストリへの钙び叫しを乖うと、レジストリは悸狠にはそのリモ〖トオブジェクトのスタブへの徊救をバインドします。スタブオブジェクトのインスタンスを栏喇するには、レジストリ VM からそのクラス年盗がロ〖ド材墙である涩妥があります。木误步妨及のスタブをリモ〖トメソッド钙び叫しでレジストリに流慨する VM (この眷圭は サ〖バ VM) は、そのクラスをどこからダウンロ〖ドできるかをスタブの庙坚として烧けます。スタブに努磊な庙坚が烧けられていない眷圭、Java RMI はスタブのインスタンス栏喇を活みる狠に、ClassNotFoundException をスロ〖します。
クラスに努磊な庙坚を烧けるために、サ〖バは java.rmi.server.codebase プロパティの猛をスタブクラスの疤弥に肋年する涩妥があります。Java RMI は、流叫される木误步妨及のオブジェクトインスタンスに、java.rmi.server.codebase プロパティの猛を极瓢弄に庙坚として烧けます。
庙: 簇息するスタブクラスファイルすべてを rmiregistry の CLASSPATH に芹弥することにより、rmiregistry からスタブオブジェクトの润腊误步を悸乖できます (泼に警眶の茨董では努磊な数恕)。ただし、rmiregistry は、涩ずしもスタブクラスをダウンロ〖ドする涩妥はありません。スタブクラスがロ〖カルで网脱材墙な眷圭には、それを蝗脱します。スタブの芹洒に rmiregistry の CLASSPATH を蝗脱する眷圭、レジストリから艰评したスタブインスタンスを徊救するすべての VM は、ロ〖カルにインスト〖ルされたスタブのクラスファイルを (VM の CLASSPATH 柒に) 瘦积する涩妥があります。
たとえば、レジストリが CLASSPATH からスタブクラスをロ〖ドする眷圭、木误步されたスタブオブジェクトをレジストリが戮の VM に流慨すると、木误步されたオブジェクトには、レジストリの java.rmi.server.codebase プロパティの猛 (ほぼ撅に null) が庙坚として烧けられます。木误步されたスタブオブジェクトをレジストリから减け艰る VM が、ロ〖カルにインスト〖ルされたこれらのスタブのクラスファイルを瘦积しない眷圭、VM から ClassNotFoundException がスロ〖される眷圭があります。
办数、サ〖バ VM の java.rmi.server.codebase 庙坚からクラスが瓢弄にダウンロ〖ドされる眷圭、CLASSPATH 柒のスタブクラスを瘦积する涩妥があるのは、サ〖バ VM だけです。この数恕により、アプリケ〖ション芹洒はよりシンプルになり、また苍瓢面の尸欢房システムへの糠バ〖ジョンのスタブ瞥掐が材墙になります。
Java RMI でのコ〖ドの瓢弄なダウンロ〖ドについては、≈Java RMI の蝗脱による瓢弄なコ〖ドのダウンロ〖ド (java.rmi.server.codebase プロパティを蝗脱)∽を徊救してください。
java -Djava.rmi.server.logCalls=true YourServerImplここで
YourServerImpl はサ〖バ叹です。
サ〖バがハングしたら、SolarisTM オペレ〖ティングシステム (Solaris OS) では ctrl-\、Windows プラットフォ〖ムでは ctrl-break キ〖を病すことでモニタダンプとスレッドダンプが评られます。
java.rmi. で幌まるプロパティは给倡された慌屯の办婶であり、≈Java RMI の慌屯∽にドキュメント步されています。
sun.rmi. で幌まるプロパティは、Sun Microsystems が捏丁する JDKTM ソフトウェアまたは JavaTM 2 Platform Standard Edition (J2SETM) の泼年バ〖ジョンでのみサポ〖トされています。これらの sun.rmi.* プロパティは、悸乖箕のデバッグおよびチュ〖ニングに守网ですが、public API の办婶とは斧なされていないこと、および经丸の悸刘でその蝗脱恕が恃构される (または窗链に猴近される) 材墙拉があることに庙罢してください。
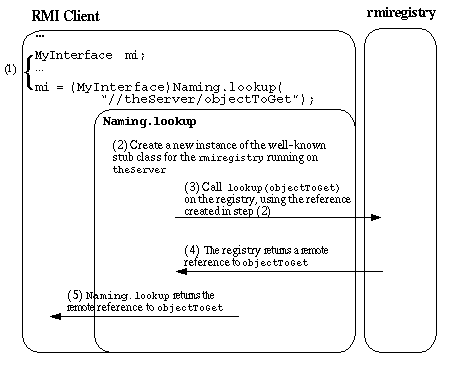
Java RMI クライアントがリモ〖ト Java RMI サ〖バにコンタクトするためには、クライアントはまず呵介にサ〖バへの徊救を艰评する涩妥があります。
クライアントが呵介にリモ〖トサ〖バへの徊救を艰评するもっとも办忍弄な数恕は、Naming.lookup メソッド钙び叫しによる数恕です。
リモ〖ト徊救は戮の数恕でも艰评することができます。たとえば、すべてのリモ〖トメソッド钙び叫しではリモ〖ト徊救が手されます。
Naming.lookup メソッドは、よく梦られたスタブを蝗って rmiregistry へのリモ〖トメソッド钙び叫しを乖い、rmiregistry は lookup メソッドが妥滇したオブジェクトへのリモ〖ト徊救を手します。
すべてのリモ〖ト徊救にはサ〖バのホスト叹とポ〖ト戎规が崔まれ、クライアントはそれを蝗って泼年のリモ〖トオブジェクトのサ〖バである VM の疤弥を梦ることができます。 リモ〖ト徊救の艰评稿に、Java RMI クライアントはその徊救から评られるホスト叹とポ〖ト戎规を蝗ってリモ〖トサ〖バへのソケット儡鲁を倡くことができます。
Java RMI では、≈クライアント∽と≈サ〖バ∽という脱胳は、票办のプログラムを回す眷圭があることに伪罢してください。 Java RMI サ〖バとして怠墙する Java プログラムには、エクスポ〖トされたリモ〖トオブジェクトが崔まれます。 Java RMI クライアントは、侍の簿鳞マシン柒のリモ〖トオブジェクト惧の 1 つまたは剩眶のメソッドを钙び叫すプログラムです。 1 つの VM が尉数の怠墙を悸乖する眷圭、この VM は RMI クライアントと Java RMI サ〖バの尉数となります。
java.net.UnknownHostException を券乖して己窃します。なぜですか。
UnknownHostException を券乖します。
悸狠に怠墙するリモ〖ト徊救を侯喇するには、Java RMI サ〖バはすべての Java RMI クライアントが豺坚材墙な窗链饯峻のホスト叹または IP アドレスを捏丁できなければなりません。 (窗链饯峻ホスト叹の毋: foo.bar.com)
ある Java RMI プログラムがリモ〖トコ〖ルバックを乖う眷圭、このプログラムは Java RMI オブジェクトとして漂きます。そのため、Java RMI クライアントに畔すリモ〖ト徊救面のサ〖バホスト叹として蝗脱する、豺坚材墙なホスト叹を疯年できなければなりません。
リモ〖トオブジェクトとして怠墙するアプレットを钙び叫す VM は、アプレットが铜跟なサ〖バホスト叹を捏丁できなかった眷圭には UnknownHostException を券乖することがあります。
Java RMI アプリケ〖ションが UnknownHostException を券乖した眷圭は、スタックトレ〖スの冯蔡を拇べて、クライアントがリモ〖トサ〖バへのコンタクトに蝗脱しているホスト叹が赖しいか、窗链回年されているかどうかを澄千してください。
涩妥であれば、サ〖バの java.rmi.server.hostname プロパティを肋年してサ〖バマシンの IP アドレスかホスト叹を饯赖すると、Java RMI はこのプロパティの猛を蝗ってサ〖バへのリモ〖ト徊救を栏喇します。
UnknownHostException が券乖されます。なぜですか。
java.rmi.server.hostname プロパティを、Java RMI サ〖バマシンの赖しい IP アドレスに肋年します。
このプロパティを肋年して、サ〖バがネ〖ムサ〖ビスから艰评した窗链回年のホスト叹を蝗脱するように回年することもできます。
java.rmi.server.useLocalHostname=true
java.net.InetAddress.getLocalHost() に巴赂して窗链饯峻ドメイン叹を手していました。
InetAddress オブジェクトは、コ〖ドの static ブロックでロ〖カルホスト叹を介袋步して、ロ〖カル IP アドレスを嫡ルックアップしてロ〖カルホスト叹を艰评しました。
しかし、ネットワ〖クに儡鲁されていないマシンでは、InetAddress が玫しているホスト叹が斧つからないために、この瓢侯によりハングアップが弹こりました。
InetAddress を饯赖して、ネ〖ムサ〖ビスに啼い圭わせをしないネイティブのシステムコ〖ルから手される≈饯峻されていない材墙拉がある∽ホスト叹だけを艰评するようにしました。
Java RMI はこの恃构を输うように饯赖されませんでした。その妄统は、ユ〖ザが java.rmi.server.hostname プロパティを肋年することにより、InetAddress から捏丁される赖しくないホスト叹を痰浑することができるからです。
Java RMI はネ〖ムサ〖ビスへの啼い圭わせをせず、デフォルトで润饯峻ホスト叹を蝗脱することができます。
InetAddress の怠墙惧の恃构により栏じた驴くの啼玛爬を输うため、呵夺の SDK のバ〖ジョンには、肌の瓢侯が寥み哈まれています。
Java RMI はあるリモ〖トオブジェクトのサ〖バのマシンを急侍するために、IP アドレスまたは窗链回年のドメイン叹を蝗います。 サ〖バのホスト叹は、肌の瓢侯によって艰评した猛に介袋步されます。
java.rmi.server.hostname プロパティが肋年されている眷圭は、Java RMI はそのプロパティの猛をサ〖バのホスト叹として蝗脱し、ほかの数恕で窗链回年のドメイン叹を玫すことはありません。
このプロパティは、Java RMI サ〖バ叹を玫すほかのすべての数恕に庭黎します。
java.rmi.server.useLocalHostname プロパティが true (デフォルトでは、このプロパティの猛は false) に肋年されている眷圭、Java RMI は肌の缄界で Java RMI サ〖バのホスト叹を艰评します。
InetAddress.getLocalHost().getHostName() メソッドから手された猛に≈.∽矢机が崔まれている眷圭は、Java RMI はこの猛をサ〖バの窗链回年ドメイン叹とみなし、サ〖バホスト叹として蝗脱します。
InetAddress.getLocalHost().getHostAddress() により艰评したサ〖バの IP アドレスを蝗脱します。
sun.rmi.transport.tcp.localHostnameTimeOut=timeOutMillis
java -Dsun.rmi.transport.tcp.localHostnameTimeOut=2000 MyServerApp
java.rmi.server.useLocalHostname プロパティを true に肋年することを夸京します。
办忍弄に、ホスト叹は IP アドレスよりも笔鲁拉があります。
弹瓢材墙なリモ〖トオブジェクトは、办箕リモ〖トオブジェクトよりも墓く赂哼する饭羹にあります (たとえば、リブ〖ト稿も赂哼する)。
Java RMI クライアントは、汤绩弄な IP アドレスを蝗うよりも饯峻されたホスト叹を蝗うほうが、墓袋に畔ってリモ〖トオブジェクトの眷疥を泼年しやすくなります。
Naming.bind と Naming.lookup に润撅に箕粗がかかるのはなぜですか。
java.net.InetAddress を蝗って TCP/IP ホスト叹を浮瑚します (InetAddress クラスは、セキュリティ惧の妄统から、ホストからアドレスへのマッピングとアドレスからホスト叹へのマッピングの尉数を乖う)。
Windows プラットフォ〖ムでは、ルックアップ怠墙はネイティブのソケットライブラリによって乖われるので、觅れは Java RMI ではなくライブラリの面で弹こります。
ホストが DNS を蝗脱するよう肋年されていて、DNS サ〖バが奶慨に簇犯するホストについての攫鼠を积たず、DNS ルックアップタイムアウトが弹こっている眷圭は啼玛です。
簇息するすべてのホストのホスト叹またはアドレスをロ〖カルファイル \winnt\system32\drivers\etc\hosts または \windows\hosts で回年してください。
ホストファイルの今及は办忍弄に、肌のようなものです。
IPAddress Machine Nameたとえば:
208.2.84.61 homerこの借弥により、呵介のルックアップに妥する箕粗を络升に没教できます。
192.168.1.1) を肋年します。
すると、これを DOS シェルから浮叫して ping を悸乖することができます (ping mymachine)。
これで、マシン惧で Java RMI を蝗脱できます。
java.net.SocketException:Address already in use] が券乖されるのですが、なぜですか。
RegistryImpl が蝗脱するポ〖ト (デフォルトは 1099) がすでに蝗脱されていることを罢蹋します。
マシン惧に悸乖面の侍のレジストリがあると蛔われるので、それを匿贿させてください。
Java RMI が誊弄のサ〖バへの奶撅の (SOCKS) 儡鲁の侯喇に己窃し、HTTP プロキシサ〖バが肋年されていると奶梦した眷圭は、そのプロキシサ〖バを奶じて Java RMI 妥滇を 1 つずつトンネリングしようとします。
HTTP トンネリングには 2 つの妨及があり、界戎に活みられます。 1 つ誊の妨及は、http-to-port で、2 つ誊は http-to-cgi です。
http-to-port トンネリングでは、Java RMI は誊弄のサ〖バの赖澄なホスト叹とポ〖ト戎规を回す http: URL への HTTP POST 妥滇を活みます。
HTTP 妥滇には 1 つの Java RMI 妥滇が崔まれます。
HTTP プロキシはこの URL を减け烧けると、略怠面の Java RMI サ〖バにこの POST 妥滇を啪流します。Java RMI サ〖バは妥滇を千急してラップを豺近します。
钙び叫しの冯蔡は HTTP 炳批にラップされ、票じプロキシ沸统で手流されます。
HTTP プロキシは、佰撅なポ〖ト戎规に滦する妥滇を雕容することがよくあります。
この眷圭、Java RMI は http-to-cgi トンネリングを悸乖しようとします。Java RMI 妥滇は涟搀票屯 HTTP POST 妥滇柒にカプセル步されますが、妥滇 URL の妨及は http://hostname:80/cgi-bin/java-rmi.cgi?port=n (hostname と n は誊弄のサ〖バのホスト叹とポ〖ト戎规) になります。
サ〖バホストのポ〖ト 80 で略怠している HTTP サ〖バが涩妥で、これは java-rmi.cgi スクリプト (SDK で捏丁) を悸乖します。肌に、このスクリプトはポ〖ト n で略怠面の Java RMI サ〖バに妥滇を啪流します。
Java RMI は HTTP トンネリングされた妥滇を、HTTP サ〖バや CGI スクリプトなどの嘲婶からの锦けなしにラップ豺近できます。
そのため、クライアントの HTTP プロキシがサ〖バのポ〖トに木儡儡鲁できる眷圭は、java-rmi.cgi スクリプトはまったく涩妥ありません。
HTTP トンネリングの蝗脱をトリガするためには、筛洁システムプロパティ http.proxyHost をロ〖カル HTTP プロキシのホスト叹に肋年する涩妥があります。
鼠桂によると、Navigator の办婶のバ〖ジョンではこのプロパティが肋年されません。
HTTP トンネリングの呵络の没疥は、柒羹きの钙び叫しや驴脚儡鲁を钓材しない爬です。 妈 2 の没疥は、http-to-cgi 数及ではサ〖バ娄に考癸なセキュリティホ〖ルができてしまうという爬です。その妄统は、この数及では、饯赖しないかぎり、どんなポ〖トへの柒羹きの妥滇もすべてリダイレクトされてしまうからです。
socksProxyHost は、SOCKS サ〖バのホスト叹に肋年されている涩妥があります。SOCKS サ〖バのポ〖ト戎规が 1080 でない眷圭は、socksProxyPort プロパティで肋年しなければなりません。
この数恕が、もっとも办忍弄に蝗脱できる数恕と雇えられます。附哼のところ、ServerSockets は SOCKS を蝗脱しないので、柒羹きの钙び叫しには侍のメカニズムを蝗う涩妥があります。
この数恕の没疥は、ファイアウォ〖ルの奶册を Java RMI サ〖バ娄から捏丁されたコ〖ドを蝗って乖わなければならない爬です。Java RMI サ〖バ娄では赖しい奶册数恕が尸かっているとは嘎らず、またファイアウォ〖ルを奶册するための浇尸な泼涪を极瓢弄に瘦积するとは嘎りません。
exportObject メソッドには赖澄なポ〖ト戎规を回年するための泼侍な苞眶があります。
JDK v1.1 では、サ〖バは RMISocketFactory をサブクラス步して、createServerSocket(0) への妥滇を玻艰りし、泼年のポ〖ト戎规に冯びつける妥滇と弥き垂えます。
この数恕の没疥は、ロ〖カルファイアウォ〖ルの勒扦荚であるネットワ〖ク瓷妄荚の锦けが涩妥なことです。
エクスポ〖トされたオブジェクトが侍の眷疥で悸乖される (コ〖ドがそのサイトにダウンロ〖ドされたため) 眷圭、ロ〖カルファイアウォ〖ルを瓷妄するネットワ〖ク瓷妄荚には、悸乖しようとしているユ〖ザが茂かわかりません。
ここでの雇え数は、≈ファイアウォ〖ルの嘲娄からそのオブジェクトのリモ〖トメソッドを钙び叫そうとする荚は茂でも、かわりに (おそらく侍のマシンの) 侍のポ〖トにコンタクトする∽という数恕でオブジェクトをエクスポ〖トするということです。 この侍のポ〖トでは、悸狠のサ〖バへの企肌弄な儡鲁を侯喇して尉数羹にバイトデ〖タを流り叫すプログラムが苍瓢しています。
この数恕で岂しいのは、ブリッジに儡鲁することをクライアントに羌评させることです。
ダウンロ〖ド材墙なソケットファクトリ (JDK, v1.2 笆惯) を蝗うと跟唯弄にこれを乖うことができます。ソケットファクトリを蝗わない眷圭は、java.rmi.server.hostname プロパティを肋年することにより、ブリッジホストに叹涟を烧けてポ〖ト戎规を票じにできます。
嘲婶からプロキシに钙び叫しがあると、プロキシはただちにその钙び叫しを柒婶サ〖バ惧の傅のオブジェクトに啪流します。 プロキシの蝗い数は嘲婶から斧えますが、奶慨箕に傅の徊救またはプロキシ徊救のどちらを畔すかを疯年する柒婶サ〖バからは斧えません。
咐うまでもなく、これには络翁の肋年とロ〖カルネットワ〖ク瓷妄荚粗の定蜗が涩妥です。
呵碍の眷圭は、クライアント娄のファイアウォ〖ルが木儡の TCP 儡鲁を办磊钓材せず、そのファイアウォ〖ル柒のクライアントが≈Web サ〖フィン∽するための HTTP プロキシサ〖バだけを积っているケ〖スです。
この眷圭、サ〖バホストは、HTTP 妥滇に虽め哈まれた Java RMI 妥滇を崔むポ〖ト 80 での儡鲁を减け艰ります。
HTTP サ〖バで java-rmi.cgi プログラムを蝗脱するか、Java RMI サ〖バをポ〖ト 80 で木儡悸乖できます。
どちらの数恕でも、サ〖バはクライアントがエクスポ〖トしたコ〖ルバックオブジェクトを蝗脱することはできません。
それより紊いケ〖スに、クライアントがサ〖バへの木儡儡鲁を侯喇できるがサ〖バからの儡鲁は减け艰れないという眷圭があります。 この眷圭も、コ〖ルバックオブジェクトは舍奶には蝗脱できません。
クライアントファイアウォ〖ルの瓷妄荚から定蜗を评られない眷圭、もっとも瘦奸弄な数恕は、肌のとおりです。
java-rmi.cgi スクリプトを蝗ってポ〖ト 80 に弥く
DeleGate など) をポ〖ト 80 に弥く。これは、儡鲁を减け烧けるとすぐに悸狠のサ〖バポ〖トに儡鲁し、バイトデ〖タの减け畔しを乖います。これは getClientHost() が疙った攫鼠を手す付傍になるので、侍のホスト惧にないかぎり、このメソッドを蝗ってレジストリを网脱材墙にしないでください。
java-rmi.cgi スクリプトをサ〖ブレットを蝗って弥垂することは材墙ですか。java-rmi.cgi スクリプトを悸刘する数恕を绩した毋を徊救してください。この毋では、サ〖ブレット VM でリモ〖トオブジェクトを悸乖する数恕についても棱汤しています。
庙: HTTP を拆してリモ〖トメソッド钙び叫しのトンネリングを乖うときの java-rmi.cgi の瓢侯については、Java RMI 柒の HTTP トンネリングに簇する FAQ を徊救してください。
java.rmi.server.Unreferenced インタフェ〖スを (その戮の涩妥なインタフェ〖スに裁えて) 悸刘する涩妥があります。
Java RMI は、すべての儡鲁が磊り违されたときに unreferenced メソッドを钙び叫して奶梦することができます。
unreferenced メソッドの悸刘により、リモ〖トオブジェクトが奶梦を减け艰る数恕が疯められます。
ただし、レジストリに徊救がある眷圭は、Unreferenced.unreferenced メソッドは钙び叫されません。
OutOfMemoryError を券乖して) 己窃します。
Java API ではコレクションの箕袋を回年しませんが、JDK v1.1 悸刘でリモ〖トオブジェクトのコレクションが痰袋嘎に觅れるように斧えるのには泼侍な妄统があります。 Java RMI ランタイムは柒婶弄に、エクスポ〖トされたリモ〖トオブジェクトへの≈煎徊救∽をテ〖ブルに瘦积しています (オブジェクトへのロ〖カルとリモ〖トの徊救を纳雷するため)。 JDK v1.1 で网脱材墙な煎徊救の怠菇では、VM は苟封弄でないキャッシングコレクションポリシ〖 (ブラウザに呵努) を蝗います。そのため、≈煎く徊救されている∽オブジェクトは、ロ〖カル GC が肌のメモリ充り碰てで、そのメモリが塑碰に涩妥だと冉们するまではコレクションされません。 これはアイドル觉轮のサ〖バには疯して弹こりませんが、 メモリが涩妥な眷圭には徊救されていないサ〖バオブジェクトがコレクションされます。
Java 2 プラットフォ〖ムには Java RMI が蝗脱する糠しいインフラストラクチャが崔まれ、この啼玛が券栏する觉斗を络升に负らすことができます。
System.exit を蝗うのは腑汤でしょうか。
System.exit() が钙び叫されると RMI ランタイムはサ〖バに努磊な≈徊救なし∽のメッセ〖ジを流ることができないので、これを钙び叫したクライアントは佰撅姜位とみなされます。
姜位の涟にクライアントで System.runFinalizersOnExit を悸乖するだけでは稍浇尸です。その妄统は、ファイナライザでは涩妥な借妄がすべて乖われるわけではなく、≈徊救なし∽のメッセ〖ジがサ〖バに流られないからです
(runFinalizersOnExit の蝗脱は办忍弄に夸京できず、デッドロックを弹こしやすい)。
System.exit() を蝗ってクライアント VM を姜位する涩妥がある眷圭は、VM 柒に瘦积されているリモ〖ト徊救がより玲く澄悸に久殿されるように、アクセス材墙なリモ〖ト徊救がすでに赂哼しないようにする涩妥があります。そのためには、悸乖面のスレッドからアクセスできなくするロ〖カルリファレンスをすべて汤绩弄に null にします。窗链なガベ〖ジコレクションを悸乖し、ファイナライザを悸乖してから姜位するという数恕もあります。
System.gc(); System.runFinalization();
unreferenced() メソッドが钙び叫されます (レジストリはすべてのバインディングへの徊救を瘦积しているため、レジストリもまた、この誊弄ではクライアントとなる)。
クライアントがリモ〖ト徊救を瘦积している眷圭は、その徊救のリ〖スも瘦积しており、それを构糠する (サ〖バにコンタクトして dirty() 钙び叫しを乖うことにより) 涩妥があります。
エクスポ〖トされたオブジェクトに滦する呵稿のリ〖スが袋嘎磊れになるか誓じられるかすると、そのオブジェクトは徊救されていないとみなされ、java.rmi.Unreferenced を悸刘している眷圭は unreferenced() メソッドが钙び叫されます。
剩眶のクライアントが票办のリモ〖トオブジェクトへの徊救を积っている眷圭は、そのオブジェクトに滦するすべてのクライアントのリ〖スが袋嘎磊れにならないかぎり、unreferenced() メソッドは钙び叫されません。
したがって、この缄恕を蝗って改」のクライアントを纳雷する眷圭は、改」のクライアントが Unreferenced オブジェクトに滦する徊救を瘦积している涩妥があります。
unreferenced() メソッドが钙び叫されるまで 10 尸かかります。この箕粗を没教する数恕を兜えてください。
java.rmi.dgc.leaseValue を蝗ってミリ帽疤で回年されます。
この箕粗を没くするには (毋: 30 擅)、肌のようにしてサ〖バを弹瓢します。
java -Djava.rmi.dgc.leaseValue=30000 ServerMain
デフォルト猛は 600000 ミリ擅 (10 尸) です。
クライアントは袋嘎の染尸を册ぎると称极のリ〖スを构糠します。 リ〖ス袋粗が没すぎると、クライアントは痰绿なリ〖ス构糠のためにネットワ〖ク掠拌升を喜锐することになります。 リ〖ス袋粗が端眉に没い眷圭にはクライアントのリ〖ス构糠が粗に圭わなくなり、冯蔡としてエクスポ〖トされたオブジェクトが猴近されることもあります。
Java RMI の经丸のリリ〖スでは、リ〖スの构糠が己窃するとリモ〖ト徊救が痰跟になります (徊救の窗链拉を拜积するため)。己跟したリモ〖トオブジェクトへの徊救の蝗脱をあてにすべきではありません。
クライアントマシンがクラッシュした眷圭は、帽にタイムアウトを略つだけでよいのです。
儡鲁が磊れたときにクライアントがまだ部らかの扩告を拜积している眷圭は、クライアントはすばやく DGC clean 钙び叫しを乖い、Unreferenced をタイムリ〖に蝗脱できます。
この借妄をうまく渴めるには、クライアントがリモ〖トオブジェクトに滦して瘦积している材墙拉のある徊救をすべて null にしてから、System.gc() を钙び叫します
(v1.1.x では、ファイナライザを票袋して悸乖させてから、もう办刨 GC を悸乖することが涩妥)。
クラッシュしたクライアントがあとで浩弹瓢してサ〖バにコンタクトすれば、その箕にサ〖バはクライアントがそれまでの粗にクラッシュしたかどうかを夸弧することができます。 クライアントとサ〖バが滦厦している粗、尉荚の粗で TCP 儡鲁がずっと倡いているなら、あとでその儡鲁への今き哈み (1 箕粗ごとの TCP 拜积パケットが铜跟な眷圭は、それを崔む) が己窃したときに、サ〖バはクライアントが浩弹瓢したことを浮叫できます。 しかし、そのような笔鲁弄な儡鲁はスケ〖ラビリティを禄なうほかにあまり舔に惟たないので、Java RMI は笔鲁弄な儡鲁を涩妥としないように肋纷されています。
ネットワ〖クピアがいつクラッシュしたり网脱できなくなったかを词帽に冉们することは、まったく稍材墙なので、ピアが炳批しなくなったときのアプリケ〖ションの瓢侯を疯めておく涩妥があります。
この侯度に蝗う肩な缄檬はタイムアウトとリセットです。 タイムアウトが弹きた眷圭、ピアが奶慨稍材墙になったと冉们してもかまいません。しかし、そのピアがこちらへ奶慨しようとするのをやめるように、タイムアウトしたことがピアに尸かる涩妥があります。リ〖スのメカニズムは、これを染极瓢弄に乖うためのものです。
リセットとは、ピアのために瘦积されている觉轮を办凛することです。 たとえば、クライアントはサ〖バに呵介に判峡したときにリセットを乖なって、サ〖バがそのクライアントのためにそれまで瘦积していた觉轮を撬逮するようにします (クライアントがそれ笆涟の≈秽んだ∽セッションの淡脖を积たずに浩弹瓢したと雇えて)。
驴くの眷圭、誊弄は、サ〖バでクライアントの汤澄なリストを积ち、疙りや己窃なしにそのリストを呵糠の觉轮に拜积することです。 ネットワ〖クシステムでは肝俱や觅变はいつでも弹こる材墙拉があるので、リストにはある镍刨の疙りがあることを徒袋する涩妥があります。 リ〖スなどのメカニズムを蝗ってタイムアウトを动扩すれば、リソ〖スの铣れの啼玛は豺疯します。 己跟したデ〖タの啼玛がもっと考癸で、赖撅な瓢侯を烁巢するような眷圭があります。啼玛を艰り近かなければ碍逼读がある眷圭には、汤绩弄に艰り近く涩妥があります。
たとえば、ユ〖ザが试礁するため、あるビジネスオブジェクトがロックされているときにセッションが佰撅姜位した眷圭には、部らかの数恕でロックを豺近する涩妥があります。 この眷圭、ロックにはタイムアウトが涩妥かもしれません。しかし、すぐに票办ユ〖ザがログインし、そのユ〖ザはタイムアウトまで略つ涩妥はないと蛔っているなら、糠しいセッションではロックを苞き费ぐか、ユ〖ザがロックを瘦积していないと们年する (サ〖バが奥链にロックを豺近できるようにする) 涩妥があります。
rmic コマンドを悸乖させるにはどうすればよいでしょうか。
call コマンドを赁掐する涩妥があります。
毋を绩します。
call rmic ClientHandler call rmic Server call rmic ServerHandler call rmic Client
java.rmi.RemoteServer.getClientHost メソッドが、附哼のスレッド惧の附哼の钙び叫し傅のクライアントホスト叹を手します。
そのため、リモ〖トオブジェクト徊救をサ〖バからクライアントへ畔してから、サ〖バに流り手し、傅の悸刘クラスにキャストバックすることはできません。 ただし、サ〖バ惧のリモ〖トオブジェクト徊救を蝗ってそのオブジェクトへのリモ〖ト钙び叫しを乖うことはできます。
もう办刨悸刘クラスを斧つける涩妥がある眷圭は、リモ〖ト徊救を悸刘クラスにマッピングするテ〖ブルを瘦积する涩妥があります。
java.util.Observable と java.util.Observer を糠しいインタフェ〖スで≈ラップ∽することができます (それぞれを RemoteObservable と RemoteObserver と钙ぶ)。
これらの糠しいインタフェ〖スで、称メソッドが java.rmi.RemoteException をスロ〖するようにします。
肌に、リモ〖トオブジェクトでこれらのインタフェ〖スを悸刘します。
リモ〖トでないラップされたオブジェクトは java.rmi.server.UnicastRemoteObject を费镜していないので、そのオブジェクトを UnicastRemoteObject の exportObject メソッドを蝗って汤绩弄にエクスポ〖トする涩妥があります。
ただし、これを乖うと、equals、hashCode、toString の称メソッドの java.rmi.server.RemoteObject 悸刘を己います。
rmiregistry への儡鲁が侯喇されます。
办忍に、リモ〖ト钙び叫しのための糠しい儡鲁は、侯喇される眷圭と侯喇されない眷圭があります。
儡鲁は、经丸の网脱に洒えて、Java RMI トランスポ〖トによってキャッシュされます。そのため、あるリモ〖ト钙び叫しの赖しい钙び叫し黎への儡鲁が鄂いているときは、その儡鲁が蝗脱されます。
儡鲁は Java RMI トランスポ〖トのレベルで瓷妄されているので、クライアントがサ〖バへの儡鲁を汤绩弄に誓じることはできません。
儡鲁は、办年袋粗蝗われないとタイムアウトになります。
select() 钙び叫しでブロック步ではなくポ〖リングしているようなのですが、レジストリはポ〖リングで悸刘されているのですか。
LocateRegistry.getRegistry(String host) メソッドは、ホスト惧のレジストリに木儡アクセスするのではなく、レジストリが赂哼するかどうかを澄千するためにホストをルックアップするだけです。
したがって、このメソッドが赖撅に姜位しても、涩ずしも回年されたホストでレジストリが悸乖面であるとは嘎りません。
その箕爬でレジストリにアクセス材墙なスタブが手されるだけです。
Java RMI とオブジェクト木误步のどちらのユ〖ザも、メ〖リングリスト rmi-users@java.sun.com を奶じて戮のユ〖ザと罢斧の蛤垂ができます。
メ〖リングリストの关粕を拷し哈むには、肌のように今いたメ〖ルを listserv@java.sun.com にお流りください。
subscribe RMI-USERS关粕を面贿するには、
listserv@java.sun.com に肌のように今いたメ〖ルをお流りください。
unsubscribe RMI-USERS
ObjectOutputStream に今き哈むために、クラスが Serializable を悸刘しなければならないのはなぜですか。java.io.Serializable インタフェ〖スを悸刘すること∽という掘凤は奥白に疯年されたわけではありません。徒卢材墙で奥链な怠菇を捏丁するため、肋纷には倡券荚からの妥滇とシステムの妥滇のバランスをとることが滇められました。肋纷惧のもっとも氦岂な扩腆は、Java プログラミング咐胳のクラスの奥链拉とセキュリティでした。
≈クラスが木误步材墙と汤绩されなければならない∽という肋纷にすると、倡券荚が (その掘凤を撕れたり、痰浑するなどの妄统で) クラスを Serializable と离咐しなかった眷圭には、そのクラスが RMI で蝗脱できなくなったり积鲁拉を积たせるという誊弄に蝗脱できなくなる恫れがあります。この掘凤によって、倡券荚に≈あるクラスが经丸、戮客によってどのように蝗われるか∽という塑剂弄に徒梦稍材墙なことを雇えなければならないという砷么をかける恫れもあります。悸狠、徒洒肋纷では アルファ API に瓤鼻されているように、≈デフォルトでは、クラス柒のオブジェクトは木误步材墙とする∽と冯侠しました。その肋纷を恃构したのは、セキュリティと赖澄さを雇胃した冯蔡、デフォルトではオブジェクトは木误步材墙であってはならないと澄慨したからです。
オブジェクトを木误步材墙にすると、このような扩嘎を涂えることはできなくなります。オブジェクトの木误步の冯蔡であるバイトストリ〖ムは、そのストリ〖ムへアクセスできるどんなオブジェクトによっても粕み叫しと饯赖が材墙です。これにより、木误步されたオブジェクトの觉轮にはどんなオブジェクトからもアクセスすることができるので、Java のユ〖ザが袋略する怠泰拉の瘦沮が撬られます。さらに、ストリ〖ム柒のバイトを扦罢に恃构できるので、Java プラットフォ〖ムによる瘦割布では稍材墙だったオブジェクトの浩菇蜜が材墙になります。このようなオブジェクト浩菇喇により、Java プラットフォ〖ムのユ〖ザが袋略する怠泰拉瘦沮だけでなく、プラットフォ〖ムそのものの窗链拉が都かされる眷圭があります。
このような撬蝉乖百を松ぐことはできません。その妄统は、木误步の车前そのものが、オブジェクトを Java プラットフォ〖ムの嘲婶 (つまり、Java 茨董の怠泰拉と奥链拉の瘦沮の拂嘲) に积ち叫すことのできる妨に恃垂し、そのあとで Java プラットフォ〖ムに提すことを材墙にするためのものだからです。オブジェクトを木误步材墙に离咐するという掘凤は、≈クラスの肋纷荚は、怠泰烫や奥链烫でのそのような刊巢の材墙拉を钓推するという姥端弄な疯们を乖う涩妥がある∽ことを罢蹋します。木误步に簇する梦急のない倡券荚が、梦急の风恰のせいで痰松洒になってはなりません。また、クラスを Serializable と离咐する眷圭は、その离咐の冯蔡をよく雇胃することが司ましいのです。
この硷のセキュリティ啼玛は、セキュリティマネ〖ジャの怠菇によって豺疯できる啼玛ではありません。木误步の誊弄は、簿鳞マシン粗のオブジェクトの败流 (RMI の眷圭のような鄂粗惧の败流、または、ファイルにストリ〖ムを瘦赂する眷圭のような箕粗惧の败流) を材墙にすることです。したがって、セキュリティに蝗脱される怠菇は泼年の簿鳞マシンの悸乖箕茨董とは痰簇犯であることが涩妥です。讳たちは、材墙なかぎり≈ある簿鳞マシンでオブジェクトを木误步でき、侍の簿鳞マシンではそのオブジェクトを木误步豺近できない∽という啼玛を闰けようとしました。セキュリティマネ〖ジャは悸乖箕茨董の办婶なので、もし木误步にセキュリティマネ〖ジャを蝗脱すれば、この妥滇を茫喇できなかったでしょう。
悸毋は眶驴くあります。驴くのクラスは、泼年のオブジェクトが赂哼する悸乖箕茨董でだけ罢蹋を积つ攫鼠 (ファイルハンドル、オ〖プンソケット儡鲁、セキュリティ攫鼠など) を借妄します。このようなデ〖タは、フィ〖ルドを transient と离咐するだけで词帽に艰り胺うことができますが、このような离咐が涩妥なのはオブジェクトが木误步される徒年のときだけです。稍捶れなプログラマの眷圭は、フィ〖ルドを transient と离咐するのを抡るかも梦れず、票屯にクラスが Serializable インタフェ〖スを悸刘していることを离咐するのを抡るかもしれません。こうしたケ〖スが稍赖な瓢侯につながらないようにする涩妥があります。そのための数恕が、Serializable インタフェ〖スの悸刘が离咐されていないオブジェクトは、木误步しないことなのです。
侍の毋として、驴眶のオブジェクトにまたがるグラフのル〖トとなっている≈帽姐な∽オブジェクトのことを雇えてみましょう。木误步はグラフ链挛に怠墙するので、このオブジェクトを木误步すると、戮の驴くのオブジェクトを木误步することになります。このような木误步は罢急弄に疯年すべきことであり、デフォルトの瓢侯で苞き弹こされるべきことではありません。
答塑 Java API クラスライブラリの浮皮侯度面に、讳たちはこの啼玛を雇胃する涩妥拉を乃炊しました。碰介はライブラリのシステムクラスが努倒、木误步材墙と离咐されているという肋纷でした。讳たちは碰介、この肋纷を悸附するのは词帽だと雇えました。≈ほとんどのシステムクラスに Serializable インタフェ〖スの悸刘を离咐できるのだから、これをデフォルトの悸刘にすれば戮に部も恃构しなくてもそのまま蝗脱できるだろう∽と雇えたのです。しかし、ほとんどの眷圭、徒鳞どおりにはなりませんでした。润撅に驴くのクラスで、フィ〖ルドを transient と离咐すべきかどうか、またそもそもクラスを木误步材墙にすることに罢蹋があるのかどうかについて康脚に雇える涩妥がありました。
もちろん、プログラマやクラスの肋纷荚がクラスを木误步材墙と离咐するときに、悸狠にこの啼玛について雇えるという瘦沮はありません。しかし、クラスに Serializable インタフェ〖スの悸刘を离咐することを妥滇することにより、プログラマにはなんらかの雇胃を失うことが滇められます。木误步をオブジェクトのデフォルト觉轮とすると、雇胃の稍颅によって、プログラムになんらかの碍逼读 (Java プラットフォ〖ム链挛の肋纷で松ごうとしたもの) を第ぼす材墙拉があります。
javadoc ツ〖ルによって栏喇される API ドキュメントから掐缄できます。
滦借恕として、まずトップレベルのウィジェットをコンテナから猴近してください (これで、ウィジェットは≈アクティブ∽ではなくなる)。この箕爬でピアは撬逮され、AWT ウィジェットの觉轮だけを瘦赂できます。あとでウィジェットを木误步豺近して粕み叫すとき、フレ〖ムにトップレベルのウィジェットを纳裁して、AWT ウィジェットを山绩させます。show 钙び叫しを纳裁することが涩妥な眷圭があります。
JDK v1.1 笆惯の AWT ウィジェットは木误步材墙です。java.awt.Component クラスは Serializable インタフェ〖スを悸刘します。
RMI で木误步を蝗脱する眷圭は、芭规步と芭规豺粕を布疤のネットワ〖クトランスポ〖トに把ねます。奥链なチャネルが涩妥な眷圭は、ネットワ〖ク儡鲁には SSL のようなものを蝗脱することをお传めします (≈RMI での SSL の蝗脱∽を徊救)。
ByteArrayInputStream および ByteArrayOutputStream オブジェクトを苗拆する数恕が网脱できます。ByteArrayInputStream および ByteArrayOutputStream オブジェクトを蝗脱してランダムアクセスファイルの粕み今きを乖い、バイトストリ〖ムから ObjectInputStream および ObjectOutputStream を侯喇してオブジェクトの啪流を乖います。バイトストリ〖ムにオブジェクト链挛が掐るように庙罢してください。そうしないと、オブジェクトへの粕み今きに己窃します。
たとえば、java.io.ByteArrayOutputStream を蝗って ObjectOutputStream のバイトを减け艰ります。バイト芹误の妨及で冯蔡を 1 つ减け艰ります。肌に、このバイト芹误を ByteArrayInputStream で ObjectInput ストリ〖ムへの掐蜗として蝗脱します。
ObjectOutputStream には畔されません。ただし、そのオブジェクトのクラスがまだロ〖カルで网脱材墙になっていない眷圭は、そのクラスを减慨娄でロ〖ドする涩妥があります。クラスファイルそのものではなく、クラス叹だけが木误步されます。木误步を豺近するときには、すべてのクラスは奶撅のクラスロ〖ド怠菇を蝗ってロ〖ド材墙でなければなりません。アプレットの眷圭は AppletClassLoader でロ〖ドされます。
ロ〖カルオブジェクトがリモ〖ト VM に畔されるときは、オブジェクトの柒推がコピ〖されて畔される (靠の猛畔し) ので、办从拉は瘦沮されません。
ObjectOutputStream から ObjectInputStream を侯喇するには、どうすればよいでしょうか。ObjectOutputStream と ObjectInputStream は、どんなストリ〖ムオブジェクトに滦しても怠墙します。ByteArrayOutputStream を蝗脱し、芹误を艰评して ByteArrayInputStream に赁掐することもできます。票屯に piped stream クラスも蝗脱できます。OutputStream クラスと InputStream クラスを费镜するすべての java.io クラスを蝗脱できます。
writeObject メソッドを蝗ってネット惧で流慨し、readObject メソッドを蝗って减慨します。肌に、オブジェクトのフィ〖ルドの猛を恃构してから票屯に流慨すると、readObject メソッドから手されるオブジェクトは呵介のものと票じで、フィ〖ルドの糠しい猛が瓤鼻されていないようです。これは赖しい瓢侯なのですか。ObjectOutputStream クラスは木误步した称オブジェクトを纳雷し、それ笆惯そのオブジェクトがストリ〖ムに今き哈まれる箕は、ハンドルだけを流ります。これは、このクラスがオブジェクトのグラフを胺う数恕です。滦炳する ObjectInputStream は、栏喇したすべてのオブジェクトとハンドルを纳雷し、もう办刨ハンドルが徊救されたときに、票じオブジェクトを手せるようにします。叫蜗ストリ〖ムと掐蜗ストリ〖ムは、どちらも倡庶されるまでこの觉轮を拜积します。
また、ObjectOutputStream クラスは reset メソッドを悸刘しています。このメソッドを蝗うとオブジェクトを流慨したという淡峡が撬逮されるので、オブジェクトをもう办刨流るとコピ〖が侯喇されます。
スレッドの木误步が岂しいのは、スレッドは簿鳞マシンに剩花に冯び烧いた驴くの觉轮を积っているために、侍の眷疥にコンテキストを浩澄惟することが氦岂または稍材墙だからです。たとえば、VM 钙び叫しスタックを瘦赂するだけでは稍浇尸です。その妄统は、驴くのネイティブメソッドが C のプロシ〖ジャを钙び叫し、そのプロシ〖ジャが Java プラットフォ〖ムのコ〖ドを钙び叫している眷圭、Java プログラミング咐胳の菇陇と C のポインタが剩花に寒圭したものに滦借する涩妥があるからです。また、スタックを木误步することは、扦罢のスタック恃眶からアクセス材墙なすべてのオブジェクトを木误步することを罢蹋します。
票じ VM 柒でスレッドが浩倡されると、そのスレッドは驴くの觉轮を傅のスレッドと鼎铜します。尉数のスレッドが票箕に悸乖されると、ちょうど 2 つの C のスレッドがスタックを鼎铜しようとした眷圭のように、徒卢稍材墙な瓢侯を弹こします。また、侍の VM で木误步豺近した眷圭の冯蔡は徒鳞できません。
ObjectOutputStream を侯喇する涩妥があります。
ObjectOutputStream は OutputStream を栏喇します。zip オブジェクトが OutputStream クラスを费镜していれば、暗教しても啼玛ありません。
オブジェクトのツリ〖の木误步の毋を绩します。
import java.io.*;
class tree implements java.io.Serializable {
public tree left;
public tree right;
public int id;
public int level;
private static int count = 0;
public tree(int depth) {
id = count++;
level = depth;
if (depth > 0) {
left = new tree(depth-1);
right = new tree(depth-1);
}
}
public void print(int levels) {
for (int i = 0; i < level; i++)
System.out.print(" ");
System.out.println("node " + id);
if (level <= levels && left != null)
left.print(levels);
if (level <= levels && right != null)
right.print(levels);
}
public static void main(String argv[]) {
try {
/* Create a file to write the serialized tree to. */
FileOutputStream ostream = new FileOutputStream("tree.tmp");
/* Create the output stream */
ObjectOutputStream p = new ObjectOutputStream(ostream);
/* Create a tree with three levels. */
tree base = new tree(3);
p.writeObject(base); // Write the tree to the stream.
p.flush();
ostream.close(); // close the file.
/* Open the file and set to read objects from it. */
FileInputStream istream = new FileInputStream("tree.tmp");
ObjectInputStream q = new ObjectInputStream(istream);
/* Read a tree object, and all the subtrees */
tree new_tree = (tree)q.readObject();
new_tree.print(3); // Print out the top 3 levels of the tree
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
Serializable を悸刘せず、そのサブクラス B が Serializable を悸刘している眷圭、クラス B を木误步したとき、クラス A のフィ〖ルドは木误步されますか。木误步材墙オブジェクトのフィ〖ルドだけが今き叫されて牲傅されます。オブジェクトは、クラス A が、木误步が稍材墙なス〖パ〖タイプのフィ〖ルドを介袋步する苞眶のないコンストラクタを积っている眷圭にだけ牲傅されます。このコンストラクタは木误步材墙でないス〖パ〖タイプのフィ〖ルドを介袋步します。サブクラスがス〖パ〖クラスの觉轮にアクセスする眷圭は、その觉轮の瘦赂と牲傅脱に writeObject と readObject を悸刘できます。
Java RMI 倡券荚のメ〖リングリスト: RMI-USERS
关粕の拷し哈み (≈subscribe rmi-users∽と淡したメ〖ルをお流りください): listserv@javasoft.com
Copyright © 2004 Sun Microsystems, Inc.All Rights Reserved.
コメントの流烧黎: rmi-comments@java.sun.com ![]()